

Value stream management. If you’ve spent any time on the internet as part of your job in DevOps, it will have become blatantly obvious that there are many people out there who truly believe you should be value mapping your way to DevOps bliss.
Main takeways
- Value stream mapping is very useful and complements DevOps
- It needs whole organization buy-in to work
- It also requires plenty of time and brainpower
- VSM needs to be maintained over time
- No time? Do an initial VSM assessment and use it as a snag list
As a productivity technique stemming from Japanese manufacturing and closely tied into the lean management model, some organizations out there are old hands at value streams, mapping and managing for some time already. If that’s not the path your organization has taken already, however, it might still seem an unfamiliar (and dare we say time-consuming) way to spend your DevOps time.
So, is value stream mapping a DevOps essential, or simply a “nice to have - if you like that kind of thing”? We take a look.
Is value stream mapping useful in DevOps-first orgs?
Is it useful? That’s probably your first question and there is only one answer - sure, there’s no doubt - value stream mapping is very useful. DevOps looks to optimize business value and value stream mapping looks to find the problems with the flow of value. They are closely related and mutually beneficial. Value stream mapping is a tool that can help maximize and improve the contribution of DevOps.
Some thinkers in the field of DevOps feel even more strongly. Marc Rix, SAFe Fellow and Curriculum Product Manager at Scaled Agile, says that value stream management is THE most important tool in DevOps:
“Business value is the ultimate goal of DevOps, and value begins and ends with the customer. DevOps needs to optimize the entire system, not just parts of it. Flow should be Lean across the entire organization, and Value Stream mapping is a Lean tool” .
Seeing value stream mapping through the same lens as visibility will help sketch out exactly where it lies in your world of DevOps. The method is another way of seeing where all the blockers, hindrances, and obstacles lie on the road to providing a seamless journey from idea to finished product. Many of these blockers will be ones that can be solved or improved by applying DevOps thinking - greater collaboration, fewer silos, automation potential, and improved visibility to name but a few.
 VSM maestra, Mary Poppendieck, gives a masterclass on the subject
VSM maestra, Mary Poppendieck, gives a masterclass on the subject
Is VSM the right move for your organization?
While there’s no doubt that value stream management is very helpful to DevOps-first teams and organizations, there are one or two things that deserve attention before you charge ahead.
Much like DevOps aims to optimize the software delivery process from end to end, value stream mapping aims to chart it end to end. If there is limited buy-in across your organization, your results will be limited too. While both approaches are best carried out in a holistic way (across a whole organization), if there isn’t generalized take-up, DevOps can be applied wherever possible without ill effect. VSM, however, must be applied to the system in its entirety, or it is close to useless. Do you have this buy-in in your team? Without it, you may find yourself struggling.
Secondly, managing and mapping the value stream is no simple task. While there are apps, books, and videos to help you in your task, it remains a big job that gets bigger as your organization does. As an IT leader, you already have your hands full - do you really have the schedule - and mind - space to devote to the skillful maintenance of your value stream?
To map or not to map?
If you decide that value stream mapping is the right way forward for your situation, the actual mechanics of creating and managing one shouldn’t be problematic. The internet is awash with value stream mapping tools, plans, articles, and advice. There are books, videos, and even courses. You really won’t find yourself stuck.
Where the doubt will enter is in companies - perhaps smaller - that are unsure if they have the bandwidth or resources to complete and maintain the task along with their other responsibilities. At the very least, take some time to familiarize yourself with the theory behind it and some of the ways you might go about actually doing it in your organization.
While value stream management needs to be an ongoing process that takes account of changes over time, the initial completion of a value stream assessment can provide a good baseline and point of departure. The assessment can give you a list of areas or problems that need attention, many of which can inform the direction of your next steps in DevOps - sort of like a snag list for your organization.
Summing up
Value stream mapping and management is clearly an approach of huge value to most enterprises - and those that embrace DevOps solutions and tools have some of the best opportunities for solving the problems that it may reveal.
Even so, much like DevOps, VSM works best when it can truly assess an organization on a global scale, taking all the aspects that contribute or detract from value flow into account. If that’s not possible, either due to a lack of buy-in or resources, it may be better to sidestep the process in the short term, instead of concentrating on the changes you already know will have an impact, saving your VSM energy for a later stage where more stakeholders are able to appreciate the fact that to be truly impactful, both VSM and DevOps work best when there is organization-wide cooperation.
Interested in finding out more ways that you can help bring business value to your company via DevOps? Download our free ebook, DevOps Business Value: prove it or lose it.
{{cta('9794bab6-6c2f-4a7e-8f3f-7c90969b525d','justifycenter')}}
...
TL;DR
Infra Import, launched last week, marks an important milestone in the ability to use Cycloid to create infrastructure as code and industrialize deployments even when using legacy code.
The problem
Infra Import sidesteps the age-old problems that arise when trying to manage your infrastructures through your cloud provider’s console or - perhaps even worse - trying to create your own Terraform from scratch. The console can result in wasted effort, error, and infrastructure drift. It’s hard to scale and when your infrastructures get more complex, it just leads to more complicated problems. If you’re brave enough to create your own Terraform, your devs risk boredom and frustration. That’s if you’re even lucky enough to have a DevOps engineer willing to try - something that many organizations struggle with.
The solution
We’ve launched Infra Import as part of Cycloid. Based on our open-source tool, TerraCognita, it’s an IaC automation and project generator that allows you to manage your manually-deployed cloud infrastructure with Cycloid. It automatically creates StackForms, Pipelines, and your Terraform and .tfstate files.
You can see where we’re going, right? Because Infra Import does this job automatically, the DevOps you do have don’t need to spend their precious time on the job, and, well, if you don’t have many DevOps engineers, you can get the job done anyway. Not everyone wants to become a DevOps engineer and, even if they do, it’s not usually a speedy process. Thanks to Infra Import, however, this won’t be a problem for your organization, no matter where it is along the road to DevOps. You can help non-expert people start with Infrastructure as Code, ensure best practice is respected, and save time for the DevOps you do have.
Your existing deployments are back under your control!
We know you worry about governance, but here, there's no need for concern. Your DevOps/Infra team will always have the last word when it comes to the policies, roles, and permissions that govern your infra. They’ll have the governance they need and end-users will have the autonomy, flexibility, and simplification they want - and everyone ends up happy.
How it works
There are just a few steps between you and infrastructural bliss.
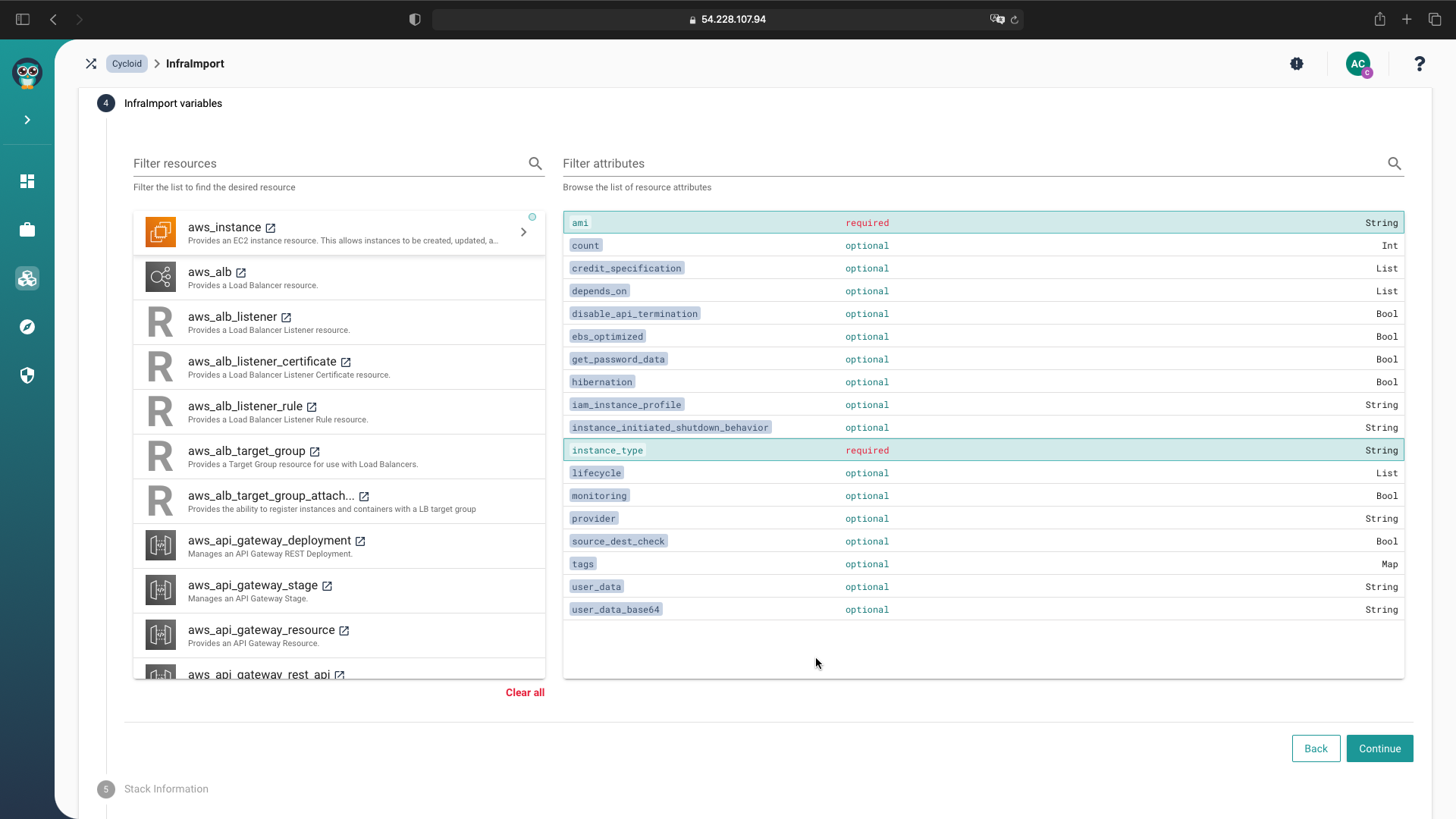
- Select your cloud provider and fill out the appropriate credentials to enable connection to the API. This will allow you to import your deployed infrastructure.
- Select which stack resources you want to import from your deployed infra.
- Name your blueprint and specify what catalog repository Infra Import should use to store the created stack.
- Enter the name of the project you want to launch, the config repository where the project configuration will be stored, and the location of your Terraform state file.
Your next steps
The best way to see Infra Import in action is to ask for a demo or a watch our demo video. Cycloid’s a multi-faceted, end-to-end enterprise tool - it's going to help you roll out a DevOps revolution in your organization. It makes no sense to give you access, a pat on the back, and leave you to your own devices for 30 days, so we ask you to get in touch so we can optimize your experience.
Infra Import helps you scale efficiently, in a reproducible and controlled manner, across all your environments - what’s not to love?! Getting in touch could be the best move you make today.
{{cta('4a329b1d-f8cc-40bb-83b1-b7fb231c5b30','justifycenter')}}
...



According to the 2021 State of DevOps Report, 80% of organizations are failing to scale DevOps adoption, and that number hasn’t changed for 4 years. We took time out to talk to Cycloid founder Benjamin Brial about the path of DevOps and why it’s not always as smooth a journey as it could be.
“Look at the top 40 businesses in the world. There are only 3 or 4 left from the “old school”, the rest of them are the new school - GAFAM (the big five, Google, Amazon, Facebook, Apple y Microsoft). They’re up there because they ship as fast as possible”.

Move fast, or perish
With that, Benjamin opens the conversation about DevOps and business value. Ultimately, he concludes that although it’s often difficult to be the person introducing and championing DevOps in a company, those who hold strong and push forward will eventually succeed. Why?
“It’s a basic business need - new customers, and the ability to satisfy those customers. If you don’t deliver a new feature, your competitor will, and people will judge based on a feature to feature comparison.”
Compare the need to deliver new features with the speed at which your competitors can deliver those very same features, and you have a dog-eat-dog world in which only the fastest survive.
“The time to delivery has accelerated - there’s a study about developing cars, they used to take 10 years, now it takes 5. We live in a world of instantaneity - everything is now, now, now”
To do that, businesses have traditionally moved straight to the IT department and invested there. Ironically, that’s what has led to one of the main problems that solutions like Cycloid try to counteract: too many tools, too much complexity.
This surfeit of tools has two knock-on problems. First, that IT is seen as a cost when it should be seen as a value. If you don’t own your tech, someone else will come and take it - it’s the technical know-how that provides the value. Benjamin gives Booking.com as an example:
“Look at Accor and compare it to Booking.com or Amazon - Booking.com don't actually produce a product, something of value, they don't build anything but they own their tech, which is why, in the market, they are unbeatable.”
What's holding you back?
Secondly, Benjamin points out that even in the best-intentioned companies, there are always walls and silos, commenting “there is always a tech/executive silo. Cycloid’s own techs sometimes don't understand me, so it’s definitely a problem for others! Every misunderstanding slows things down, but business always needs it to be faster.”
We asked Benjamin why, if the need for DevOps was so plain to see, was it still so difficult to get buy-in in certain businesses?
“DevOps culture empowers people and that's not really how the enterprise world works. Traditionally, when you want to succeed in the enterprise, you concentrate on keeping your head down and not making waves. When you bring DevOps in, you’re fighting against tradition and against the status quo, the idea that "it's always been done like this"”.
Benjamin thinks it’s primarily a comfort zone problem - it’s not that executives don’t believe in the power of DevOps, it’s more like that it’s a brave new world, and those in the C-level aren’t natives.
The way forward
He points out that enterprises consist of structures that are designed to maintain silos, concepts like departments, politics, and accountability. It takes effort to do things differently and although executives are aware that they need to do things differently, it’s hard, they’re lost, and it’s complicated!
Even so, says Benjamin “there will be resistance, but you need to push because it's the only way forward”!
Despite the difficulties, there are a number of points that give DevOps fans the upper hand. Benjamin points out that DevOps is not really a question of hard skills, it’s oriented around soft ones. Now, this isn’t entirely unproblematic - soft skills are notoriously hard to recruit for - but when you do manage to get the right people, they’re uniquely qualified for the job - both DevOps itself and championing it in the greater enterprise.
There’s great satisfaction in being the one to do this, Benjamin says: “It’s nice to be part of something bigger, building bridges and getting rid of silos”. That self-same feeling of satisfaction is also going to be one of the things that help people push DevOps forward in their company.
A parting piece of advice from the Cycloid founder? Well, actually, he has a few!
“Get your execs to the same mental place as you - evangelize more, show them the advantages of DevOps, present the benefits, reassure them that it’s not a show job. There's this idea out there that DevOps means playing with lots of alpha tools, reinventing the wheel, or playing with new tech because its "really cool". Good DevOps care about efficiency and KPIs, and they care about evangelizing DevOps to others. These are the players you want on your team."
We couldn't agree more!
{{cta('9794bab6-6c2f-4a7e-8f3f-7c90969b525d','justifycenter')}}
...
A while back, I wrote an ebook to help people work on the one part of the DevOps puzzle you can't buy, outsource, or ignore - the DevOps mindset. During my research, I found an idea that really made me laugh - even though it probably shouldn't. It was in the middle of coronavirus lockdown though, so I have my excuses.
That idea was the bus factor.
The bus factor - variously known as the truck factor or the lorry factor - is a scenario or set of circumstances that are best avoided if you're part of a team. The idea is closely linked to redundancy, but in this case, the desired redundancy is people and not machines.
If you have a team where everyone has a job, but only one person knows how to do a specific job, then the absence of one team member will bring the whole team to its knees. This is the epitome of a single point of failure, and something that should be avoided at all times.
In case you're wondering where the term the bus factor comes from, we explained it in Plan Now, Win Later:

How do you calculate the bus factor?
Luckily, you won't need any complex calculations or audits for this one. Simply take the project in question and figure out how many people need to be absent before work cannot continue. If that's just one, then you have a bus factor of 1 - and that's a dangerous thing. If it's more like 3 or 4, then you're doing pretty well!
Why should you fear a low bus factor?
Think of the bus factor as one of the many canaries in the mineshaft that will alert you to the presence of unhealthy organizational patterns in your team. Since one of the mainstays of DevOps is butter-smooth organization and progress, you can see why the bus factor is something you want to increase.
We've also got a bit of bad news. Dysfunctional organizational traits rarely happen in isolation, so if you realize that you've got a terrible bus factor then there's a real risk that you've got other problems too.
Like what?
Well, are you sure you don't have a department of pingpong players? Definite that the Ikea factor, loss aversion, and the sunk cost fallacy aren't swaying your teams' actions? If you see one, check for others - this article is a good place to start.
Close, but no banana
Until now, we've really been looking at the traditional bus factor - the single person of failure. There are more variations of the problem, however.
The hero complex
The hero complex is, once more, a single person of failure, but the difference here is that rather than the professional skills they bring to the job, it's the integral role they play in the way the team thinks and acts. Very often, this person is known as "the rockstar" and, just like leather pants, that's not a good thing.
The rockstar might not be the only person who can do a job, but they are the single person that the rest of the team rely on, turn to, and trust. When they're absent, the team loses its mettle and direction, and ends up almost as useless as one that is missing its main dev.
Look in the weeds
Ok, so far we've looked at the problems a missing person might cause, but that's because that specific person and their knowledge, experience, or personality is missing. But it can also cause serious problems when the absence of a person means more mundane things. If John goes MIA, you might not miss his mediocre coding skills, but that essential password, missing 2FA, or release approval will bring your team to a halt nonetheless.
How to prevent a low bus factor
Ok, now that we've thoroughly scared you, you may want to know what specific aspect of DevOps thinking might protect you? Well, the number one thing that will protect you from this chaos is...cross project collaboration!
Cross project collaboration
Easy in theory, hard in practice, this is essentially what DevOps is all about, except instead of breaking down silos between developers and ops engineers, you'll most likely be breaking down the silos between devs and..other devs.
This kind of bus factor often rears its head in smaller teams, where there is only one frontend person, one Android developer, and one iOS developer, for example. When Daria the frontend dev gets run over by a bus, there is no more frontend for a while. If there's no contingency plan, that will hobble your app completely.
Now, it's true that Daria has been hired for her expertise in frontend development, and it makes sense that she's especially skilled at it. That said, ensuring the whole team can at least manage the basics across the stack means that easy tasks and jobs can keep moving, preventing a massive backlog from developing in Daria's absence.
So, this is fine in theory, but how to you ensure that your whole team has full stack experience in practice? Some teams are actually quite resistant to the process, while others are open but don't exactly know where to start.
Here's our best advice:
Get buy in
You'll be fighting a losing battle if your team is completely against the idea of working across the stack. Hopefully some bus factor disasters of their own will be enough to convince them to make a change, but if not, go slowly and try to lead by example, rather than pushing them in head-first.
Reduce barrier to entry
Make sure that across all projects, you've made it as easy as possible to get started. This can mean taking a look at the technical set-up and making sure it's very smooth, ensuring documentation is up-to-date and relevant, and generally keeping everything as simple as possible.
Lead by example
Obviously, you can help by leading by example and lending a hand where needed - just bear in mind that you can set all the examples you like, but if the practical things aren't in place, you'll be fighting a losing battle.
Dedicate time to other people's projects
There are various ways to approach this, but the most popular way is usually peer or group programming. Remember, at the start there's no need to be doing anything heroic with the code - just take the opportunity to fix a bug or get familiar with new code. Once people are situated and have set themselves up as they need, they'll find it much easier to go forward alone.
Reassign people to better distribute power
If you've detected a bout of hero worship on your team, consider redistributing your rockstar - or the people around her - to make it harder to rely on her for wisdom, leadership, or inspiration. People will soon see they can rely on their own judgement quite nicely.
Automation is your friend
Less a practical tip and more a general reminder about automation, once you have solid automation in place (helped by a tool like Cycloid, for example), the bus factor becomes much less threatening. Once it's in place, you won't need your rockstar - or Bob, John, or Daria - to ensure the job gets done.
Summing up
There's one overarching message you should take from this article - cross project collaboration is key. It's important in the world of DevOps, important in resilient tech teams, and key when it comes to increasing your bus factor.
Whether your bus factor is acceptable or not, get started on encouraging your team to get some cross-stack skills. Even if you've already got them, cross-project collaboration is an active initiative that needs to be nurtured, and this might be the perfect time to take another look.
Join 2,935 other proactive DevOps fans by signing up to the Cycloid quarterly newsletter.
{{cta('da7d1a6d-80dd-41a7-8811-0ffaef8d457e','justifycenter')}}
...


Nikola, a front end developer here at Cycloid, tells us what led to our recent shake up of Roles & Policies, why what we had could be improved, and how we went about improving it.
Until recently, our Roles and Policies system used a one-to-one relation. What does it mean? It means that the user was able to assign only 1 policy for 1 entity without any link or hierarchy between those entities.
Why was that a problem?
The user had to give access to the project but also specify access to each pipeline belonging to that project. That wasn't a big deal for small projects, but as complexity increases, it becomes really cumbersome to scale and maintain. Another issue was that we were not able to create flexible complex custom user roles.How did we overcome it?
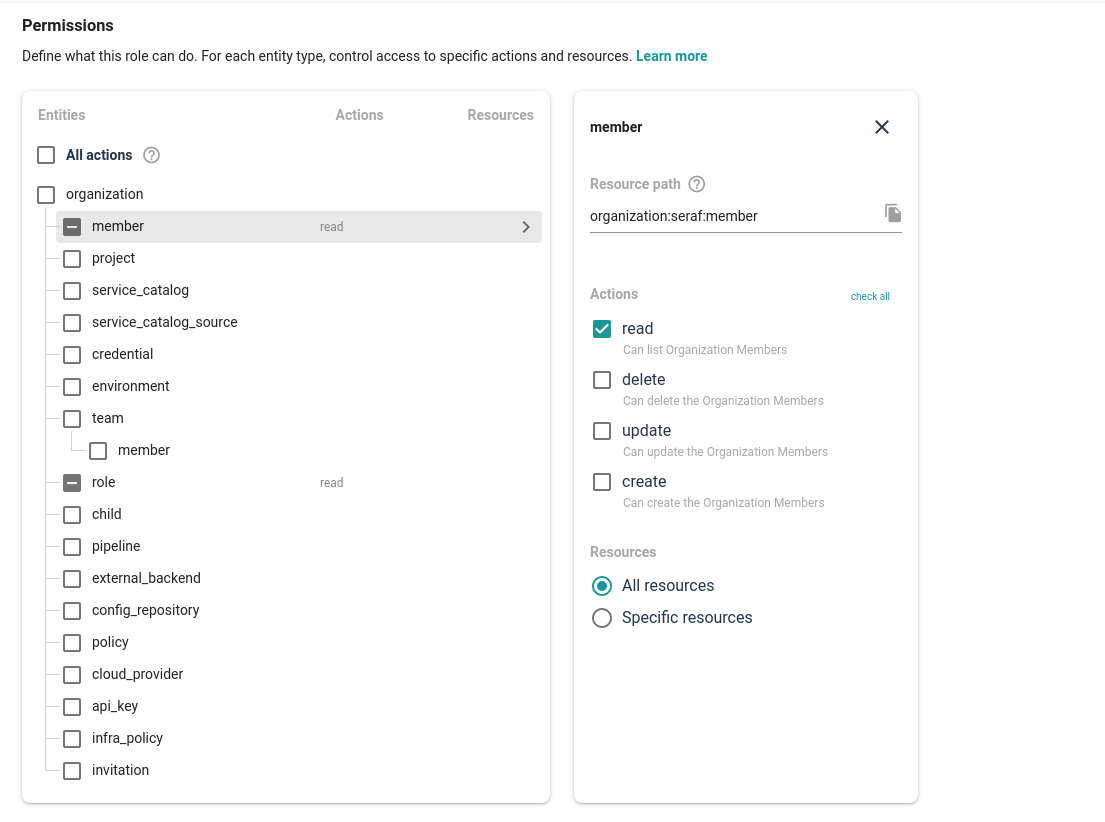
To solve the problem, we had to replace what we had with a new technology that we developed using REGO OPA (open policy agent). It provided us with scalability and opened the door for cool features we have already introduced and others that are planned for the future. One of those features is the ability to use globing. This eliminates the need to specify each resource or action and allows you to simply write policy like organization:**, which grants access to perform all actions under all resources.
How does it look now?
Now an organization can create highly flexible complex custom roles and even achieve role grouping by creating various roles and assigning them to a team. If we need to be more specific, the role can be created using system-defined actions and resources or/and with manually created actions. From a technical point of view, we now have clear ground and solid foundations for developing all the features we've planned for Roles & Policies - permissions scoping, enhanced globing and even greater flexibility.
Roles & Policies - the future
Our goal is to achieve a fully customizable and scalable solution that will enable enterprise customers to handle access to their resources. For example, as an admin user, I would like to give access to Project B and all its child entities by using globing and scoped permissions, avoiding the need to add permissions for each action on the entity manually.
One possible way of achieving this would be by the user creating a role that contains permissions to perform all actions on a specific project:
Action: `organization:<org_canonical>:project:*`
Resource: `organization:<org_canonical>:project:<project_canonical>`
That's just one example, but by moving to an OPA-based permissions system, we've ensured that there is a bright future for Roles & Policies. If you'd like to try it yourself, sign up for Cycloid's trial version, or check out the docs for more information.
Join 3,075 other DevOps enthusiasts by signing up for the quarterly Cycloid newsletter
{{cta('da7d1a6d-80dd-41a7-8811-0ffaef8d457e','justifycenter')}}




