
What is Asset Inventory Management in the Cloud?
To understand asset inventory management in the cloud, first ask yourself: What is asset inventory? Traditionally, an inventory asset referred to physical items like servers, storage devices, or networking equipment in data centers. These assets had fixed locations, purchase dates, and clearly defined lifecycles. But cloud asset inventory changes this entirely. Today, inventory is considered an asset only if you have complete visibility into it. Resources are ephemeral—virtual machines, containers, databases, and networks can appear and vanish within minutes. Without proper asset inventory management, tracking these dynamic resources becomes nearly impossible. Here's a simplified overview of how inventory management typically works, especially relevant for cloud environments: As shown, effective asset inventory management involves a clear, repeatable cycle:- Identify Assets: Discover all existing cloud resources across multiple providers.
- Record Asset Details: Capture essential details such as resource type, location, ownership, and billing information.
- Track Asset Lifecycle: Monitor assets from provisioning through active usage to eventual retirement or deletion.
- Monitor Usage & Status: Regularly track resource utilization to avoid unnecessary costs or downtime.
- Perform Regular Audits: Periodically verify resources, ensuring accurate inventory and compliance.
- Update Records: Adjust inventory records based on audit results or infrastructure changes.
- Generate Reports & Insights: Provide actionable data on resource allocation, cost, and compliance.
- Optimize Inventory: Continuously refine resource allocation and lifecycle management for improved efficiency.
What are the Challenges within Multi-Cloud Inventory?
Now in multi-cloud environments, things get even more complicated. Each provider has its own way of handling inventory, permissions, and tracking. Without a well-defined strategy, visibility becomes fragmented, and operational overhead increases. Let’s take a look at some of the challenges that teams face when trying to track assets across multiple cloud providers.Different APIs & Data Formats
AWS, GCP, Azure, and other cloud providers like Outscale and IONOS each have their own APIs and services for structuring and accessing cloud resources. While resource data is generally formatted in widely used standards like JSON or CSV, the methods for retrieving it - via CLI tools, SDKs, or direct API calls - vary significantly across providers. For example, AWS provides resource visibility through AWS Config, GCP offers its Asset Inventory service, and Azure relies on Resource Graph for querying cloud resources. Similarly, European cloud providers like Outscale and IONOS have their own APIs and tools for resource management. Despite achieving similar goals, differences in APIs, authentication mechanisms, and command-line syntax mean organizations often require custom integrations or separate scripts to consolidate inventory data across multiple clouds. This adds complexity and overhead when creating a unified, centralized asset inventory view.Access & Permissions
IAM management is already complex within a single cloud provider, but managing roles, service accounts, and permissions across multiple clouds is an entirely different challenge. A role with overly permissive access in one cloud could create a security risk, while an untracked service account in another could become an attack vector. Ensuring consistent access policies across platforms is one of the hardest parts of multi-cloud asset management.Lack of a Single Source of Truth
In most organizations, asset data is scattered. Some teams rely on AWS Config, others use GCP Asset Inventory, and a few still maintain spreadsheets to track critical resources. When data is fragmented across multiple tools and platforms, no single dashboard provides a complete picture of what exists in the cloud, making audits and compliance checks a nightmare.Scaling Inventory Processes
What works for a small environment with 50 resources quickly falls apart when you’re managing 5,000+ resources across multiple accounts and regions. Manual tracking isn’t scalable, and without automation for tagging, reporting, and asset discovery, the process becomes unmanageable. Without proper guardrails, resources get lost, permissions drift, and costs spiral out of control. To overcome these challenges, teams need a more structured, automated approach to tracking cloud assets - one that works across providers and scales with infrastructure growth.What Are the Core Approaches to Track Asset Inventory Across Clouds?
Now, let’s go through some key methods that organizations use to maintain a reliable and up-to-date asset inventory.Native Cloud Services
Each cloud provider offers built-in tools for asset tracking. While they don’t work across platforms, they provide a great visibility into resources within their own ecosystem.- AWS Config – Tracks AWS resource changes automatically and records configurations over time.
- AWS Resource Explorer – Helps search for AWS resources across accounts and regions, making it easier to find orphaned or untagged assets.
- AWS Systems Manager (SSM) Inventory – Collects metadata about EC2 instances and applications, providing insight into running workloads.
- GCP Asset Inventory – Provides a real-time view of all GCP resources, including IAM roles and permissions.
- Azure Resource Graph – Allows for large-scale queries across Azure subscriptions to track deployed resources.
IaC State Files
Infrastructure as Code (IaC) offers a provider-agnostic way to manage cloud infrastructure, making it one of the most effective strategies for multi-cloud asset tracking.- Terraform State: Terraform maintains an internal state file (terraform.tfstate) that acts as an authoritative inventory of all provisioned cloud resources. Every time Terraform provisions or modifies infrastructure, this state file is updated. You can directly query Terraform state to list all managed resources by running commands such as terraform state list.
- Pulumi State – Similar to Terraform, Pulumi stores infrastructure state in a backend that records all provisioned resources across multiple clouds. This state file acts as Pulumi's inventory source. You can query your infrastructure inventory with pulumi stack export command. This command exports state as JSON, allowing you to extract resource inventory information clearly.
Hands-On: Automating Asset Inventory with Terraform & AWS
Now, instead of relying on engineers to track cloud assets manually, we'll automate asset inventory management using AWS Config. AWS Config serves as a built-in inventory management solution for AWS by continuously recording and maintaining a detailed list of all resources in your account. Each resource created, modified, or deleted is logged in real-time, providing a comprehensive, historical inventory stored securely in an S3 bucket. Let’s go through each step one by one.Step 1: Set Up AWS Config to Track All Resources
AWS Config is a service that keeps track of every AWS resource and logs any changes. It stores these records in S3, so you can go back and see what was created, deleted, or modified at any time. First, we need an S3 bucket to store AWS Config logs. Since every S3 bucket name must be unique, Terraform adds a random suffix to ensure no naming conflicts.| provider "aws" { region = "us-east-1" } resource "random_pet" "s3_suffix" { length = 2 separator = "-" } resource "aws_s3_bucket" "config_logs" { bucket = "cyc-infra-bucket-${random_pet.s3_suffix.id}-prod" force_destroy = true } Next, we create an IAM role that allows AWS Config to write logs to this S3 bucket. resource "aws_iam_role" "config_role" { name = "config-role-prod" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [{ Effect = "Allow" Principal = { Service = "config.amazonaws.com" } Action = "sts:AssumeRole" }] }) } resource "aws_iam_role_policy_attachment" "config_s3_attach" { policy_arn = "arn:aws:iam::aws:policy/service-role/AWS_ConfigRole" role = aws_iam_role.config_role.name } Now, we enable AWS Config and tell it to track all AWS resources. resource "aws_config_configuration_recorder" "config_recorder" { name = "config-recorder-prod" role_arn = aws_iam_role.config_role.arn } resource "aws_config_delivery_channel" "config_delivery" { name = "config-channel-prod" s3_bucket_name = aws_s3_bucket.config_logs.id } resource "aws_config_configuration_recorder_status" "config_recorder_status" { name = aws_config_configuration_recorder.config_recorder.name is_enabled = true depends_on = [aws_config_delivery_channel.config_delivery] } |
| aws configservice describe-configuration-recorders |

Step 2: Enable AWS Resource Explorer
When you’re managing multiple AWS accounts, finding resources is a pain. AWS Resource Explorer makes it easier by allowing you to search for instances, databases, and other resources across all AWS accounts and regions. We enable AWS Resource Explorer using Terraform by creating an aggregated index that gathers data from all AWS accounts.| resource "aws_resourceexplorer2_index" "resource_explorer_index" { name = "resource-index-prod" type = "AGGREGATOR" } resource "aws_resourceexplorer2_view" "resource_explorer_view" { name = "resource-view-prod" scope = "ALL" } |
| aws resource-explorer-2 list-views |

Step 3: Automate Tag Enforcement with AWS Lambda & EventBridge
Many teams struggle with inconsistent resource tagging. Some engineers follow tagging rules, others forget, and some resources end up with no tags at all. Missing tags make it hard to track costs, enforce security, and find resources. To fix this, we create a Lambda function that automatically tags resources when they are created.| resource "aws_lambda_function" "tag_enforcer" { function_name = "tag-enforcer-prod" filename = "lambda.zip" source_code_hash = filebase64sha256("lambda.zip") handler = "index.handler" runtime = "python3.9" role = aws_iam_role.lambda_role.arn } |
| resource "aws_cloudwatch_event_rule" "resource_creation_rule" { name = "resource-creation-prod" description = "Triggers on new resource creation" event_pattern = jsonencode({ source = ["aws.ec2", "aws.s3", "aws.lambda"] detail-type = ["AWS API Call via CloudTrail"] detail = { eventSource = ["ec2.amazonaws.com", "s3.amazonaws.com", "lambda.amazonaws.com"] eventName = ["RunInstances", "CreateBucket", "CreateFunction"] } }) } |
| aws lambda list-functions | grep "tag-enforcer" |

Step 4: Use AWS Organizations for Multi-Account Management
If you’re managing multiple AWS accounts, keeping track of resources across accounts is a nightmare. AWS Organizations makes this easier by bringing all accounts under one umbrella, ensuring that they follow the same security and tagging rules. Terraform enables AWS Organizations to enforce account-wide policies.| resource "aws_organizations_organization" "org" { feature_set = "ALL" } |
| aws organizations describe-organization |

Step 5: Querying AWS Config for Tracked Resources
Now that AWS Config is actively tracking all resources in your AWS environment, the next step is to retrieve asset inventory reports. This helps teams understand what resources exist, their configuration history, and who owns them. To fetch all tracked AWS resources, use:| aws configservice list-discovered-resources --resource-type AWS::AllSupported --max-items 50 |
 This confirms AWS Config is tracking EC2 instances, S3 buckets, and IAM roles, along with their unique resource IDs and creation timestamps.
This confirms AWS Config is tracking EC2 instances, S3 buckets, and IAM roles, along with their unique resource IDs and creation timestamps. Step 6: Retrieve AWS Resource Configuration History
Now, tracking inventory changes over time is important for troubleshooting, security audits, and compliance tracking. To check the configuration history of an EC2 instance:| aws configservice get-resource-config-history \ --resource-type AWS::EC2::Instance \ --resource-id i-0a9b3f25c7d891e3f \ --limit 5 |
 With this setup in place, cloud asset tracking becomes a simple process. AWS Config continuously monitors resources, recording changes and storing logs in S3 for auditing, significantly simplifying Terraform-driven compliance audits and governance efforts. AWS Resource Explorer centralizes search across multiple AWS accounts and regions, making it easy to locate specific resources. AWS Lambda, triggered by EventBridge, enforces tagging policies the moment a new resource is created, ensuring consistency. AWS Organizations unifies resource management, applying governance rules across multiple accounts. Every resource is automatically recorded, searchable, and governed. Any changes are logged, ensuring compliance and security. Infrastructure scales without losing visibility, and costs stay under control by preventing unused resources from lingering. Asset management is no longer an operational burden - it runs as an integrated part of the cloud environment, keeping everything structured and predictable. Now that we’ve covered how to track and automate cloud asset inventory, there’s still one major problem - visibility across multiple clouds. Even with AWS Config, GCP Asset Inventory, and Terraform state files, asset tracking remains scattered. There’s no single place where teams can see all their cloud resources across AWS, GCP, and Azure. Searching for a resource still means jumping between multiple dashboards, and ensuring compliance and governance requires manual intervention.
With this setup in place, cloud asset tracking becomes a simple process. AWS Config continuously monitors resources, recording changes and storing logs in S3 for auditing, significantly simplifying Terraform-driven compliance audits and governance efforts. AWS Resource Explorer centralizes search across multiple AWS accounts and regions, making it easy to locate specific resources. AWS Lambda, triggered by EventBridge, enforces tagging policies the moment a new resource is created, ensuring consistency. AWS Organizations unifies resource management, applying governance rules across multiple accounts. Every resource is automatically recorded, searchable, and governed. Any changes are logged, ensuring compliance and security. Infrastructure scales without losing visibility, and costs stay under control by preventing unused resources from lingering. Asset management is no longer an operational burden - it runs as an integrated part of the cloud environment, keeping everything structured and predictable. Now that we’ve covered how to track and automate cloud asset inventory, there’s still one major problem - visibility across multiple clouds. Even with AWS Config, GCP Asset Inventory, and Terraform state files, asset tracking remains scattered. There’s no single place where teams can see all their cloud resources across AWS, GCP, and Azure. Searching for a resource still means jumping between multiple dashboards, and ensuring compliance and governance requires manual intervention. How Cycloid Handles Cloud Asset Management Across Multiple Clouds
This is where Cycloid steps in. Cycloid provides a unified asset inventory that integrates easily across multiple cloud providers. Instead of managing infrastructure separately for each cloud, Cycloid brings everything into one place, making it easier to track, standardize, and govern cloud assets. Teams managing infrastructure across multiple clouds often struggle with fragmented visibility. A resource might exist in AWS but have dependencies in GCP, and a networking component might reside in Azure. Without a single source of truth, DevOps teams end up switching between different consoles just to track their infrastructure. Cycloid eliminates this complexity by offering a centralized dashboard that consolidates all cloud assets in one place. From the dashboard, teams can:
From the dashboard, teams can: - Access their favorite projects.
- Track cloud costs across multiple cloud providers.
- Monitor carbon emissions of infrastructure.
- Check recent activity logs, consolidating events across AWS, GCP, and Azure.
- Single, unified view: Provides visibility of all cloud assets, eliminating the need to log in to multiple cloud provider platforms.
- Real-time tracking: Offers centralized tracking of resource usage, ownership, and configuration changes.
- Projects: Top-level units grouping resources across AWS, GCP, and Azure.
- Environments: Multiple isolated environments within each project, such as development, staging, or production.
- Components: Individual resources or services like virtual machines, Kubernetes clusters, databases, or networking resources deployed within environments.
- Centralized inventory: Projects and environments automatically maintain accurate resource tracking.
- Lifecycle management: Consistently track, audit, and manage infrastructure inventory across multiple clouds.
 With this structure, teams don’t need to worry about cloud provider differences. Instead of jumping between AWS, GCP, and Azure dashboards, they can create projects, define environments, and deploy infrastructure - all from one place.
With this structure, teams don’t need to worry about cloud provider differences. Instead of jumping between AWS, GCP, and Azure dashboards, they can create projects, define environments, and deploy infrastructure - all from one place.  The process of setting up infrastructure in Cycloid is pretty simple. A new project can be created and linked to a repository, allowing teams to manage configurations centrally. Ownership and permissions are defined during project creation, ensuring security and accountability.
The process of setting up infrastructure in Cycloid is pretty simple. A new project can be created and linked to a repository, allowing teams to manage configurations centrally. Ownership and permissions are defined during project creation, ensuring security and accountability.  Once a project is set up, an environment is created within it. Each environment acts as an isolated workspace for different infrastructure stages, ensuring that testing and production workloads remain separate.
Once a project is set up, an environment is created within it. Each environment acts as an isolated workspace for different infrastructure stages, ensuring that testing and production workloads remain separate.  Managing infrastructure manually across multiple clouds is inefficient. Cycloid simplifies this by offering StackForms, which allow teams to deploy cloud components using predefined templates. Instead of writing Terraform or CloudFormation scripts from scratch, teams can select a pre-configured infrastructure stack, customize parameters, and deploy their cloud resources within minutes.
Managing infrastructure manually across multiple clouds is inefficient. Cycloid simplifies this by offering StackForms, which allow teams to deploy cloud components using predefined templates. Instead of writing Terraform or CloudFormation scripts from scratch, teams can select a pre-configured infrastructure stack, customize parameters, and deploy their cloud resources within minutes.  StackForms make it easy to deploy networking, compute, storage, and security components across AWS, GCP, and Azure. Teams can define configurations directly from the Cycloid interface without needing to write complex automation scripts.
StackForms make it easy to deploy networking, compute, storage, and security components across AWS, GCP, and Azure. Teams can define configurations directly from the Cycloid interface without needing to write complex automation scripts.  After selecting a component, configurations such as credentials, project settings, network configurations, and cloud-specific parameters are applied. This ensures that infrastructure deployments remain consistent across cloud providers.
After selecting a component, configurations such as credentials, project settings, network configurations, and cloud-specific parameters are applied. This ensures that infrastructure deployments remain consistent across cloud providers.  Beyond infrastructure deployment, governance and compliance are key concerns for cloud teams. Cycloid ensures that resources follow organizational standards by enforcing consistent tagging policies, compliance checks, and security best practices. It allows security and DevOps teams to define global policies that apply across all cloud providers, reducing the risk of misconfigurations. Cloud inventory data isn’t just for viewing - it needs to be actionable. Cycloid provides an API that enables teams to interact with their cloud inventory programmatically. This API can be used to automate reporting, governance enforcement, and integration with other DevOps tools, ensuring that cloud asset data remains an integral part of infrastructure workflows. By the time everything is configured, Cycloid provides a fully unified asset inventory across all cloud providers. Instead of dealing with fragmented tools and scattered logs, organizations get a structured, scalable system for managing cloud assets efficiently. Now, cloud inventory data isn’t just for viewing - it needs to be actionable. A static inventory doesn’t provide much value if teams still need to manually track, verify, and manage cloud resources. This is where APIs come in, allowing teams to interact with cloud asset inventory programmatically, ensuring that resource data is always available for automation, governance enforcement, and integration with DevOps workflows. With the Cycloid API, teams can:
Beyond infrastructure deployment, governance and compliance are key concerns for cloud teams. Cycloid ensures that resources follow organizational standards by enforcing consistent tagging policies, compliance checks, and security best practices. It allows security and DevOps teams to define global policies that apply across all cloud providers, reducing the risk of misconfigurations. Cloud inventory data isn’t just for viewing - it needs to be actionable. Cycloid provides an API that enables teams to interact with their cloud inventory programmatically. This API can be used to automate reporting, governance enforcement, and integration with other DevOps tools, ensuring that cloud asset data remains an integral part of infrastructure workflows. By the time everything is configured, Cycloid provides a fully unified asset inventory across all cloud providers. Instead of dealing with fragmented tools and scattered logs, organizations get a structured, scalable system for managing cloud assets efficiently. Now, cloud inventory data isn’t just for viewing - it needs to be actionable. A static inventory doesn’t provide much value if teams still need to manually track, verify, and manage cloud resources. This is where APIs come in, allowing teams to interact with cloud asset inventory programmatically, ensuring that resource data is always available for automation, governance enforcement, and integration with DevOps workflows. With the Cycloid API, teams can: - Fetch real-time cloud inventory data across AWS, GCP, and Azure without logging into multiple dashboards.
- Automate infrastructure reporting, making sure all cloud assets are properly tagged, allocated, and compliant.
- Integrate with existing DevOps pipelines, so cloud resource changes trigger workflows in tools like Terraform, CI/CD platforms, or monitoring solutions.
Conclusion
With a structured approach to cloud asset management, tracking resources across hybrid and multi-cloud environments becomes seamless. Automating inventory management ensures visibility, security, and cost control, eliminating manual inefficiencies. By now, you should have a clear understanding of how to manage cloud assets effectively, keeping your infrastructure organized, compliant, and scalable.Frequently Asked Questions
What is a Hybrid and Multi-cloud Approach?? A hybrid cloud combines on-premise infrastructure with public or private cloud services, while a multi-cloud approach uses multiple cloud providers (AWS, Azure, GCP) to avoid vendor lock-in and improve resilience. What is the Role of a Cloud Asset Inventory? A cloud asset inventory provides visibility, tracking, and governance over all cloud resources, helping teams monitor usage, enforce security policies, and optimize costs. What is the Best Way to Record Inventory? Automating asset tracking using cloud-native tools (AWS Config, GCP Asset Inventory), Infrastructure as Code (Terraform state files), and centralized dashboards ensures accuracy and real-time updates....
What is Cloud Governance?
Cloud governance is the set of rules and controls that organizations use to manage cloud resources efficiently. These rules ensure that every resource follows security, compliance, and operational standards. Without governance, AWS environments can quickly become disorganized, and non-compliant.Risks of Poor Cloud Governance
Without a governance framework, misconfigurations and security gaps can easily go unnoticed by your teammates. Some common risks include:- Overly Permissive IAM Policies – Users and services may have more access than necessary, increasing security risks.
- Uncycd Storage – Publicly accessible S3 buckets or unencrypted EBS volumes may expose sensitive data.
- Weak Network Security – Poorly configured security groups and VPC rules can expose cloud resources to the internet.
- Compliance Failures – Without continuous monitoring, resources may drift away from industry standards like CIS, NIST, PCI-DSS, and ISO 27001.
The Role of Compliance Audits in Enforcing Governance Standards
A compliance audit is a structured process to check if cloud environments follow security and regulatory policies. These audits help organizations:- Detect Misconfigurations Early – Regular checks help identify security risks before they are exploited.
- Ensure Compliance with Industry Standards – Frameworks like SOC 2, HIPAA, and GDPR require strict security policies. Compliance audits verify adherence.
- Prevent Configuration Drift – Infrastructure may change over time. Audits ensure that cloud resources stay aligned with security baselines defined by the organization.
Defining Cloud Governance Policies with Terraform
Cloud environments require well-defined governance policies to maintain security, enforce compliance, and prevent misconfigurations. Without strict policy enforcement, AWS environments can become fragmented, introducing security risks and operational inconsistencies. Terraform provides a way to codify governance policies, ensuring they are consistently applied across all infrastructure deployments. Governance policies in AWS typically focus on identity and access management (IAM), storage security, and network security. Each of these domains plays a crucial role in enforcing security best practices. Let’s examine how Terraform helps implement and enforce these governance policies at scale.IAM Policies: Enforcing Least Privilege Access
IAM is the foundation of cloud security, controlling who can access resources and what actions they can perform. Over-permissioned IAM policies are a major security risk, often leading to privilege escalation and unauthorized data access. Enforcing the principle of least privilege (PoLP) ensures that identities only have the minimal permissions required to function. Terraform allows organizations to define IAM policies programmatically, ensuring uniform enforcement across environments. A common security requirement is restricting access to S3 buckets by assigning read-only permissions to a specific IAM role.| Effect = "Allow" Action = ["s3:GetObject"] Resource = "arn:aws:s3:::my-cyc-bucket/*" |
Storage Governance: Securing S3 and Enforcing Encryption
Misconfigured storage is one of the leading causes of data breaches in the cloud. Publicly accessible S3 buckets, unencrypted storage, and missing logging mechanisms can expose sensitive information. Terraform allows organizations to enforce storage security policies at the infrastructure level. S3 bucket policies can be configured to block public access, ensuring that no accidental exposure occurs. Encryption can also be enforced to protect data at rest, ensuring compliance with CIS, PCI-DSS, and NIST standards.| block_public_acls = true block_public_policy = true restrict_public_buckets = true |
Network Governance: Restricting Traffic and Enforcing VPC Security
Unrestricted network access poses a significant security threat in AWS environments. Misconfigured security groups, network ACLs (NACLs), and VPC peering rules can expose resources to the public internet, increasing the attack surface. Terraform enables teams to define security group rules as part of infrastructure deployments, ensuring that only authorized traffic flows into cloud workloads. If an organization wants to allow SSH access only from a trusted IP address, this can be enforced at deployment.| from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["203.0.113.0/32"] |
Scaling Governance Policies with Terraform
Manually managing security policies across multiple AWS accounts and environments introduces inconsistency and risk. Terraform provides a way to standardize governance policies, ensuring that security configurations remain declarative, version-controlled, and reproducible. By integrating Terraform with CI/CD pipelines, organizations can enforce security policies before deployment, preventing misconfigurations from ever reaching production. Terraform can also be used with AWS Config to detect configuration drift, alerting teams when resources deviate from the approved governance baseline. Effective governance requires continuous enforcement, real-time monitoring, and automated remediation. By using Terraform to manage IAM, storage, and network policies, organizations can proactively cyc their AWS environments, enforce compliance at scale, and eliminate any kind of security gaps within the infra.Automating Compliance Audits Using Terraform
Manually auditing cloud environments for compliance is inefficient, prone to errors, and difficult to scale. Security teams often rely on periodic reviews to identify misconfigurations, but by the time these audits are completed, the infrastructure may have already drifted away from compliance standards. Terraform addresses this challenge by automating compliance audits, ensuring that governance policies are continuously enforced and deviations are detected early. Compliance frameworks like CIS, NIST, and PCI-DSS provide security benchmarks that organizations must follow to cyc their cloud environments. Terraform enables teams to define these governance policies as code and validate infrastructure configurations against them. By integrating Terraform with AWS services like AWS Config, organizations can automatically detect and remediate non-compliant resources, reducing the risk of security incidents.Defining Compliance Checks in Terraform
The first step in automating audits is defining compliance baselines in Terraform. These baselines outline the required configurations for cloud resources, ensuring that security policies are applied consistently across deployments. For example, a compliance rule might state that all S3 buckets must be encrypted and block public access by default. Terraform can enforce this by defining security policies at the infrastructure level.| block_public_acls = true block_public_policy = true restrict_public_buckets = true |
Terraform’s Declarative Approach to Governance Audits
Terraform follows a declarative model, meaning infrastructure is defined in code and any deviations from the expected state are flagged. This makes it easier to enforce governance policies, as Terraform continuously compares the actual infrastructure state with the desired configuration. With the Terraform plan, teams can preview infrastructure changes before applying them. If a change violates compliance policies - such as enabling public access on an S3 bucket - Terraform will flag it, preventing accidental misconfigurations. This approach acts as an automated security check, ensuring that governance rules are followed throughout the infrastructure lifecycle.Integrating AWS Config with Terraform for Continuous Monitoring
While Terraform helps enforce governance at deployment, AWS Config ensures that compliance is maintained over time. AWS Config continuously monitors AWS resources and detects any drift from security baselines. When integrated with Terraform, AWS Config can automatically trigger alerts or remediation actions when a resource becomes non-compliant. For example, if an S3 bucket’s encryption setting is disabled, AWS Config can detect the change, and Terraform can be used to automatically reapply the correct security settings.| resource "aws_config_config_rule" "s3_encryption_check" { name = "s3-encryption-check" source { owner = "AWS" source_identifier = "S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED" } } |
Generating Governance Compliance Reports with Terraform
Governance audits often require detailed reporting to demonstrate compliance with regulatory frameworks. Terraform outputs can be used to generate compliance reports, providing visibility into security controls and infrastructure state. Terraform can output a list of non-compliant resources, allowing security teams to track violations and remediate them efficiently.| output "non_compliant_resources" { value = aws_config_config_rule.s3_encryption_check.arn } |
Proactive Compliance Auditing with Terraform
By automating compliance checks with Terraform, organizations move from a reactive to a proactive approach in cloud governance. Instead of waiting for audits to uncover security gaps, Terraform ensures that compliance policies are enforced before deployment and continuously monitored after deployment. With a combination of policy-as-code, AWS Config, and automated reporting, Terraform enables organizations to maintain a cyc, compliant, and well-governed AWS environment at scale.Hands-On: Implementing Cloud Governance with Terraform
Governance policies ensure that cloud environments remain cyc, compliant, and well-structured. However, defining policies alone is not enough - these rules must be enforced at every stage of infrastructure deployment. Terraform enables organizations to implement governance controls as code, ensuring that security policies are applied consistently across all AWS environments. This section focuses on setting up Terraform for governance enforcement, applying IAM policies to restrict access, securing S3 storage, enforcing network security rules, integrating AWS Config for compliance monitoring, and generating governance audit reports. By the end of this implementation, Terraform will automate governance policies, detect any deviation from security baselines, and ensure that AWS resources remain compliant.Setting Up Terraform for Governance Enforcement
Before applying governance policies, Terraform needs to be configured to interact with AWS. The first step is to verify AWS authentication by running:| aws sts get-caller-identity |
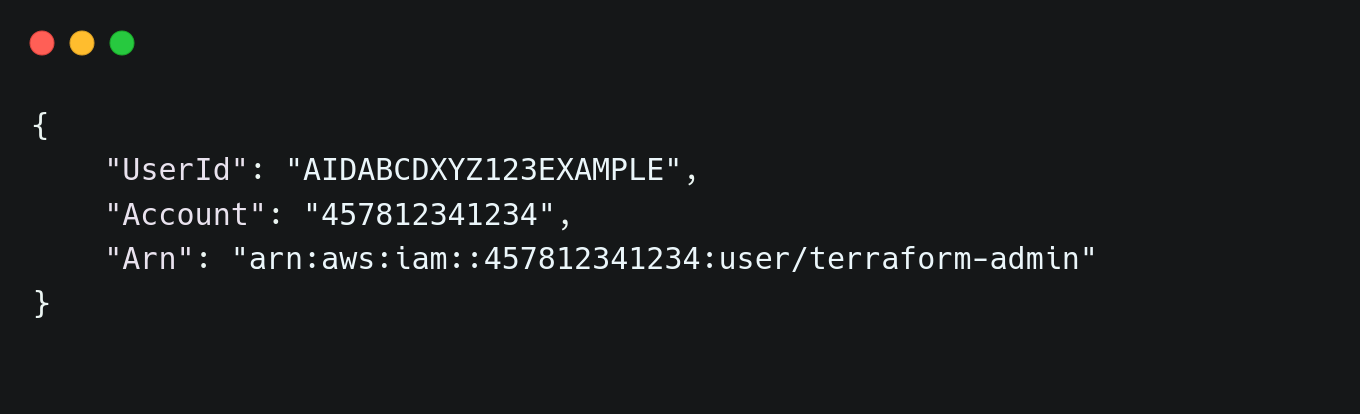 Once authentication is confirmed, Terraform must be initialized to prepare the environment for infrastructure provisioning. Running the terraform init command installs required provider plugins and ensures Terraform is ready to apply governance policies. With Terraform set up, governance policies can now be applied to enforce security standards across AWS resources.
Once authentication is confirmed, Terraform must be initialized to prepare the environment for infrastructure provisioning. Running the terraform init command installs required provider plugins and ensures Terraform is ready to apply governance policies. With Terraform set up, governance policies can now be applied to enforce security standards across AWS resources. Enforcing IAM Policies with Terraform
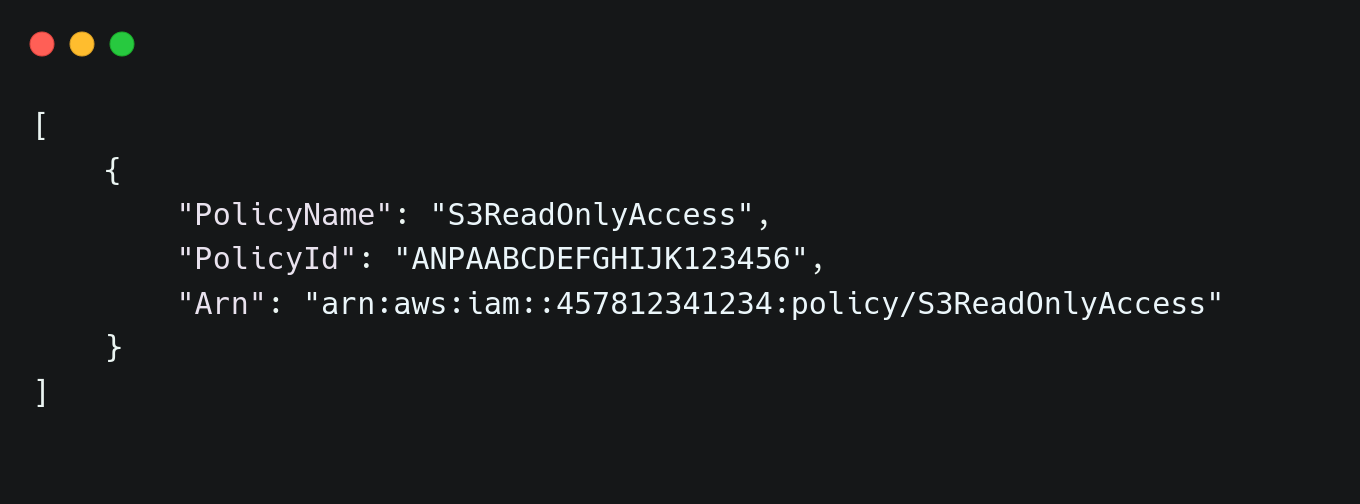
Identity and Access Management (IAM) controls who can access cloud resources and what actions they can perform. Overly permissive IAM policies increase security risks, making it crucial to follow the principle of least privilege. Terraform allows IAM policies to be defined as code, ensuring uniform enforcement across environments. To restrict access to an S3 bucket, a policy can be defined that allows only read-only permissions. This prevents unauthorized modifications while ensuring data accessibility.| resource "aws_iam_policy" "s3_read_only" { name = "S3ReadOnlyAccess" description = "Provides read-only access to S3"policy = jsonencode({ Version = "2012-10-17", Statement = [ { Effect = "Allow", Action = ["s3:GetObject"], Resource = "arn:aws:s3:::prod-data-cyc/*" } ] }) } |
| aws iam list-policies --query "Policies[?PolicyName=='S3ReadOnlyAccess']" |
Securing S3 Buckets and Enforcing Encryption
Publicly accessible S3 buckets and unencrypted storage create vulnerabilities that can lead to data breaches. Terraform ensures that all S3 buckets are encrypted and block public access by default. A governance-compliant bucket configuration includes encryption enforcement and access restrictions.| resource "aws_s3_bucket" "cyc_bucket" { bucket = "org-finance-data" }resource "aws_s3_bucket_server_side_encryption_configuration" "cyc_bucket_encryption" { bucket = aws_s3_bucket.cyc_bucket.id rule { apply_server_side_encryption_by_default { sse_algorithm = "AES256" } } } resource "aws_s3_bucket_public_access_block" "bucket_block" { bucket = aws_s3_bucket.cyc_bucket.id block_public_acls = true block_public_policy = true restrict_public_buckets = true } |
| aws s3api get-public-access-block --bucket org-finance-data |
Enforcing Network Security with Terraform
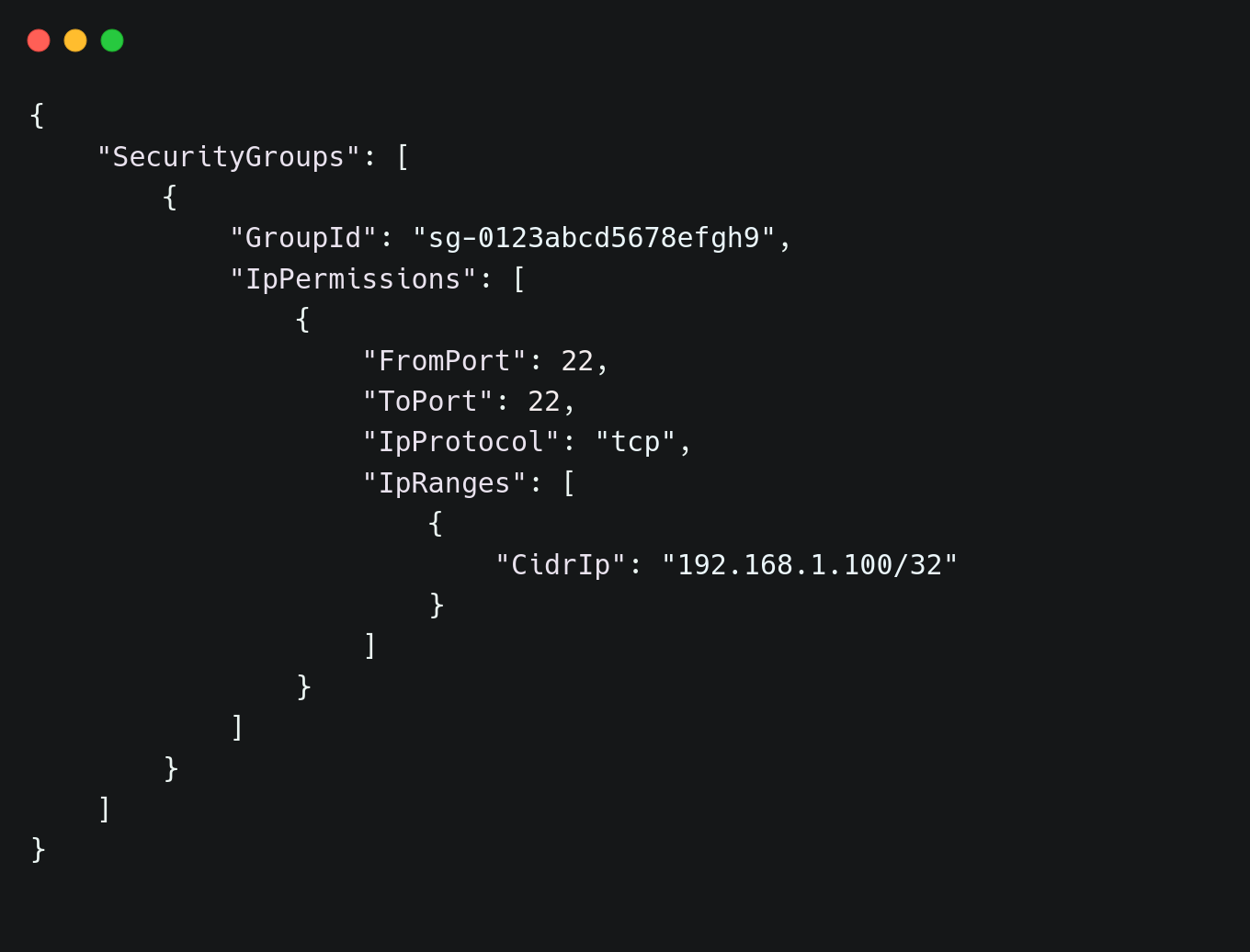
Security groups play a crucial role in restricting network access. Misconfigured security groups can expose services to the public internet, making them vulnerable to unauthorized access. To enforce network security, Terraform can define strict inbound and outbound rules. For SSH access, the following configuration allows connections only from a specific trusted IP:| resource "aws_security_group" "restricted_sg" { name = "restricted_ssh" description = "Allows SSH access only from trusted IP" vpc_id = aws_vpc.main.idingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["192.168.1.100/32"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } |
| aws ec2 describe-security-groups --group-ids sg-0123abcd5678efgh9 |
Integrating AWS Config for Governance Monitoring
AWS Config helps detect configuration drift and ensures that resources remain compliant with governance rules. Terraform can define a compliance rule to check if all S3 buckets are encrypted.| resource "aws_config_config_rule" "s3_encryption_check" { name = "s3-encryption-check" source { owner = "AWS" source_identifier = "S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED" } } |
| aws configservice describe-compliance-by-config-rule --config-rule-name s3-encryption-check |
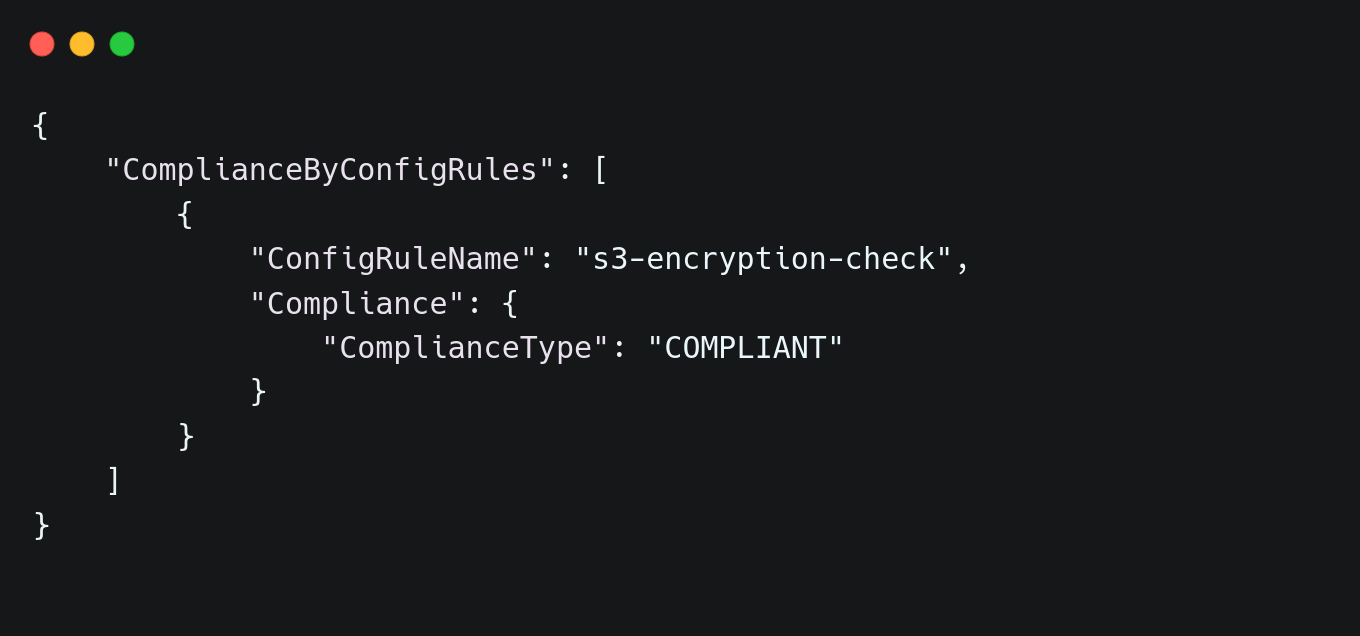 By implementing these governance policies with Terraform, security and compliance enforcement become an automated, integral part of cloud infrastructure. IAM restrictions, S3 encryption, and network security controls make sure that AWS environments remain protected. With AWS Config monitoring configuration drift, governance becomes a continuous process rather than a reactive measure. This approach ensures that misconfigurations are prevented before they become security risks, maintaining a cyc cloud environment at all times.
By implementing these governance policies with Terraform, security and compliance enforcement become an automated, integral part of cloud infrastructure. IAM restrictions, S3 encryption, and network security controls make sure that AWS environments remain protected. With AWS Config monitoring configuration drift, governance becomes a continuous process rather than a reactive measure. This approach ensures that misconfigurations are prevented before they become security risks, maintaining a cyc cloud environment at all times. Best Practices for Continuous Cloud Governance
Implementing governance policies with Terraform ensures a cyc cloud environment, but following best practices strengthens compliance, reduces misconfigurations, and prevents security drift.Version-Control Governance Policies
Storing Terraform configurations in Git allows teams to track changes, enforce approvals, and maintain an audit trail. Using branching strategies, such as GitFlow, prevents unauthorized modifications to governance rules.Secure Terraform State Files
Terraform state files contain sensitive information, including IAM roles, database credentials, and networking details. Enabling encryption for state files and using remote storage solutions like AWS S3 with state locking in DynamoDB makes sure that state files are not tampered with or accessed unintentionally.Conduct Regular Compliance Audits
Infrastructure changes, whether intentional or accidental, can introduce misconfigurations. Automating compliance checks using AWS Config and Terraform plan ensures that deviations from governance baselines are identified and corrected early.Integrate Terraform into CI/CD Pipelines
Running terraform validate and terraform plan as part of the pipeline ensures that changes adhere to security policies before reaching production. Combining Terraform with policy-as-code tools like Open Policy Agent (OPA) further strengthens governance by enforcing predefined rules within pipelines. Making sure that every infrastructure change adheres to governance policies is often difficult. Many security teams rely on manual checks, pre-deployment security reviews, and post-deployment audits to enforce compliance. While these methods can identify misconfigurations, they introduce delays and inconsistencies. A common challenge in governance enforcement is the lack of real-time validation. Organizations often detect non-compliant configurations only after resources are already deployed, leading to costly rollbacks and security risks. Without a centralized mechanism to enforce security, IAM, and networking policies before deployment, teams struggle with operational inefficiencies and increased exposure to misconfigurations. One approach to address this challenge is to integrate compliance checks into Terraform workflows. Security teams write custom validation scripts that run during the Terraform execution process, scanning configurations for policy violations. While this method improves governance, it introduces complexity. These scripts must be maintained, updated as security policies evolve, and integrated into CI/CD pipelines. Additionally, enforcement varies across teams, as different engineers may interpret policies differently.Enforcing Cloud Governance with Cycloid Infra Policies
Cycloid’s Infra Policies simplify governance enforcement by providing a centralized, automated approach to policy validation. Rather than relying on custom scripts, like running OPA commands repeatedly or waiting for team members to review your configurations, Cycloid allows DevOps teams to define governance rules as code. These policies are then automatically enforced during the Terraform plan execution, preventing misconfigurations before they make it to production. The first step in implementing governance policies with Cycloid is to create an Infra Policy in the Cycloid console. Navigate to Security -> InfraPolicies, where teams can define policy rules to enforce compliance standards.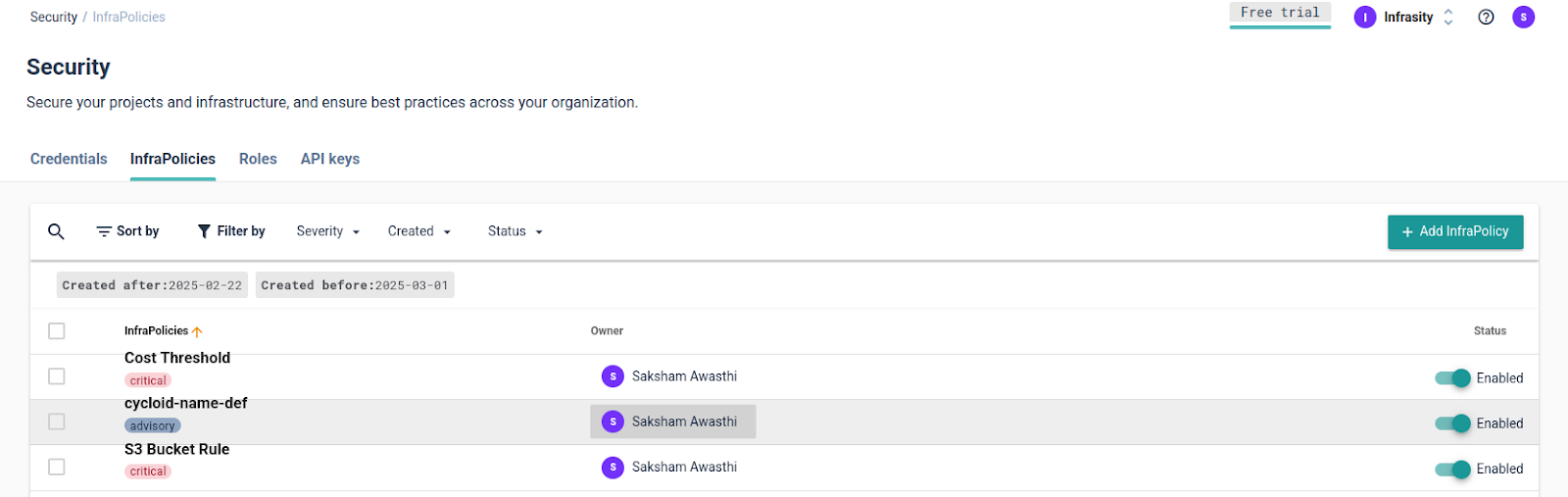 These policies are written in Rego, and in the image below, you can see an example of a Rego policy that stops deployment if the resource cost exceeds the defined limit. With this policy in place, Cycloid will block the deployment right at the Terraform plan stage.
These policies are written in Rego, and in the image below, you can see an example of a Rego policy that stops deployment if the resource cost exceeds the defined limit. With this policy in place, Cycloid will block the deployment right at the Terraform plan stage. 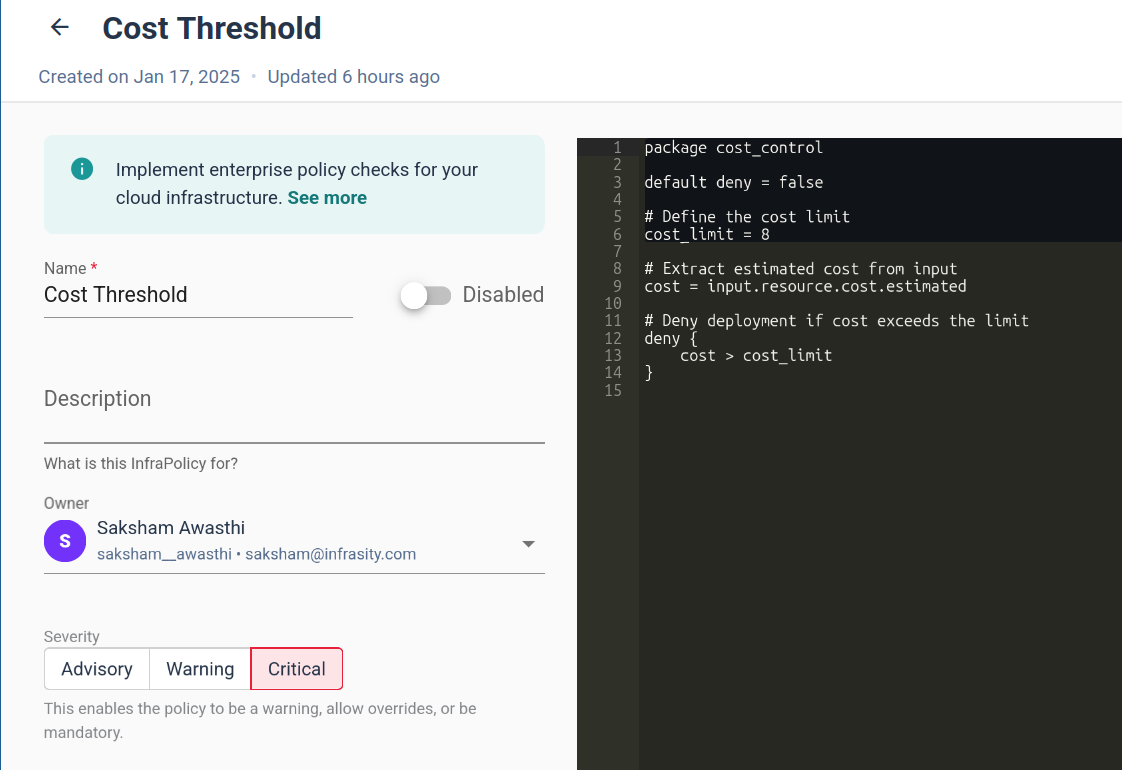 For more examples of how to write InfraPolicies in Rego in Cycloid’s Infrapolicy, refer to the documentation. Once the policy is created, Cycloid validates infrastructure changes. However, before this happens, you need to go to the project and environment sections in Cycloid and then fill out the resource details, such as the bucket name and region if you’re creating a new S3 bucket. This step makes sure that Cycloid can evaluate your infrastructure configurations properly.
For more examples of how to write InfraPolicies in Rego in Cycloid’s Infrapolicy, refer to the documentation. Once the policy is created, Cycloid validates infrastructure changes. However, before this happens, you need to go to the project and environment sections in Cycloid and then fill out the resource details, such as the bucket name and region if you’re creating a new S3 bucket. This step makes sure that Cycloid can evaluate your infrastructure configurations properly. 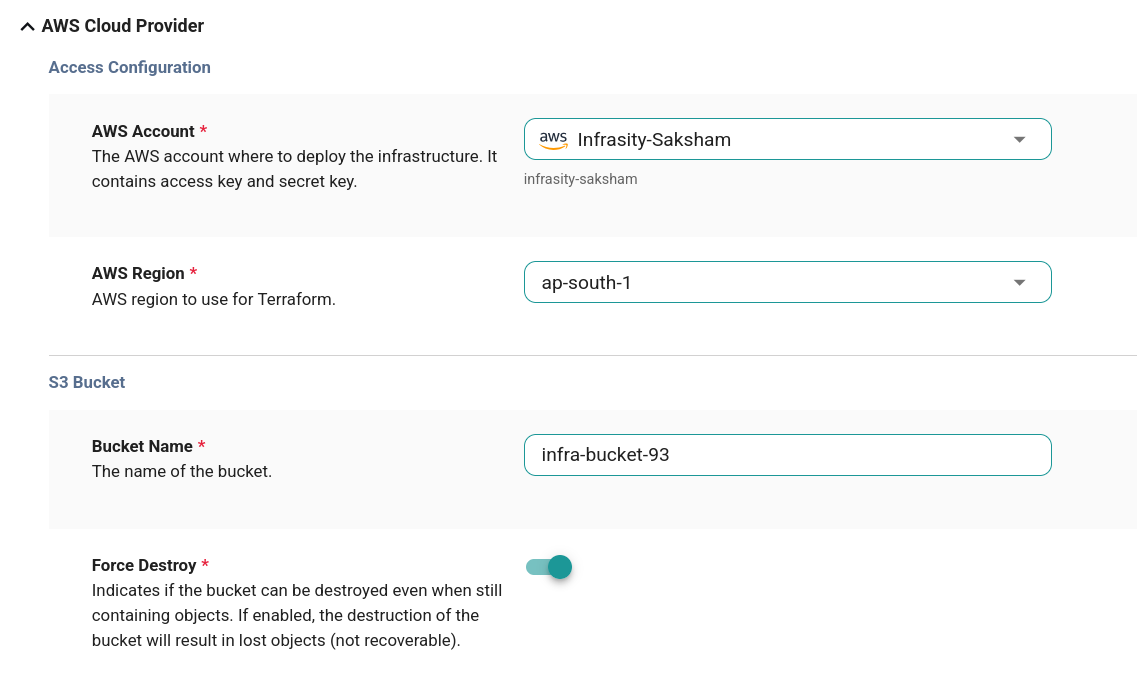 In order to use InfraPolicy within the pipeline, you'll need to configure the cycloid-resource resource within your pipeline as follows:
In order to use InfraPolicy within the pipeline, you'll need to configure the cycloid-resource resource within your pipeline as follows: | - name: cycloid-resource type: registry-image source: repository: cycloid/cycloid-resource tag: latest |
| - name: infrapolicy type: cycloid-resource source: feature: infrapolicy api_key: ((cycloid_api_key)) api_url: ((cycloid_api_url)) env: ((env)) org: ((customer)) project: ((project)) |
| - put: infrapolicy params: tfplan_path: tfstate/plan.json |
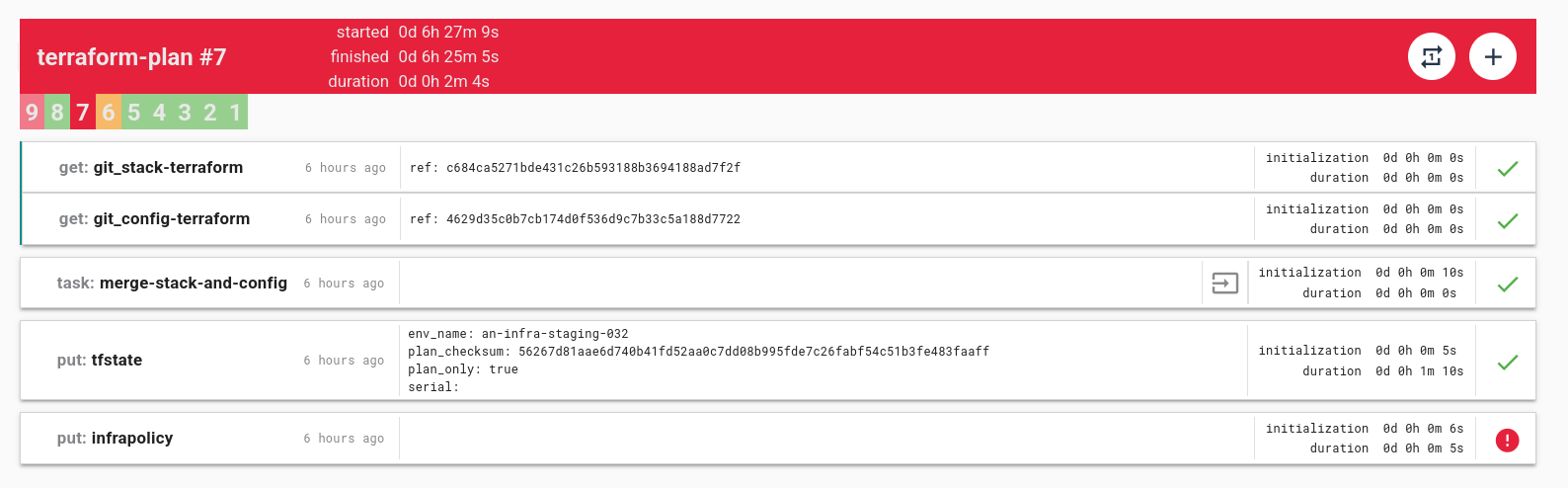 This proactive policy enforcement reduces the risk of misconfigurations slipping through and removes the need for manual post-deployment audits. With Cycloid, governance is built into the deployment process, making it seamless and reliable. Cycloid Infra Policies ensure that governance enforcement isn’t an afterthought but an integral part of the infrastructure lifecycle. By defining policies centrally and enforcing them automatically, organizations can scale security best practices across teams without increasing operational overhead. This structured approach helps improve compliance, reduces errors, and allows DevOps teams to focus on delivering stable, secure infrastructure. Cycloid doesn’t stop at just InfraPolicy for governance. With its comprehensive cloud governance solutions, Cycloid enables you to manage everything from security and cost control to compliance at a large scale. For more information, check out Cycloid's Cloud Governance solutions.
This proactive policy enforcement reduces the risk of misconfigurations slipping through and removes the need for manual post-deployment audits. With Cycloid, governance is built into the deployment process, making it seamless and reliable. Cycloid Infra Policies ensure that governance enforcement isn’t an afterthought but an integral part of the infrastructure lifecycle. By defining policies centrally and enforcing them automatically, organizations can scale security best practices across teams without increasing operational overhead. This structured approach helps improve compliance, reduces errors, and allows DevOps teams to focus on delivering stable, secure infrastructure. Cycloid doesn’t stop at just InfraPolicy for governance. With its comprehensive cloud governance solutions, Cycloid enables you to manage everything from security and cost control to compliance at a large scale. For more information, check out Cycloid's Cloud Governance solutions. Conclusion
Now, you should have a clear understanding of how Terraform automates governance, enforces compliance, and prevents misconfigurations. Integrating policy checks early ensures cyc, auditable, and compliant cloud environments.Frequently Asked Questions
1. Which AWS Cloud Service Enables Governance Compliance, Operational Auditing, and Risk Auditing of Your AWS Account?
AWS CloudTrail is the primary service that enables governance, compliance, operational auditing, and risk auditing of AWS accounts. It continuously records AWS API calls, providing visibility into user activity across AWS services. CloudTrail logs include details such as the identity of the caller, the time of the API call, the source IP address, and the request parameters. These logs help monitor changes, detect unusual activities, and ensure compliance with internal security policies and external regulations like GDPR, HIPAA, and SOC 2.2. Which AWS Service Continuously Audits AWS Resources and Enables Them to Assess Overall Compliance?
AWS Config is a managed service that continuously audits and assesses the configuration of AWS resources to ensure they comply with security best practices and governance policies. It tracks configuration changes in resources such as EC2 instances, security groups, IAM roles, and S3 buckets, maintaining a historical record of configurations.
Organizations use AWS Config to:
- Assess compliance with industry standards such as PCI-DSS, NIST, ISO 27001, and CIS benchmarks.
- Detect misconfigurations and remediate them using AWS Config Rules and AWS Systems Manager.
- Monitor resource relationships and dependencies for better visibility into infrastructure changes.
3. Which AWS Service Supports Governance, Compliance, and Risk Auditing of AWS Accounts?
AWS Audit Manager is a fully managed service that simplifies compliance assessments and risk auditing by automating the collection of evidence across AWS resources.
The key capabilities of AWS Audit Manager include:
- Automated compliance reporting for frameworks such as SOC 2, ISO 27001, PCI-DSS, GDPR, and HIPAA.
- Continuous evidence collection to track user activity, resource changes, and security configurations.
- Customizable assessment frameworks to align with internal governance policies.
Organizations use Audit Manager to simplify compliance processes, reduce manual effort in audits, and ensure that security controls are continuously monitored and assessed.
4. What Are Governance, Risk, and Compliance in Cloud Computing?
Governance, Risk, and Compliance (GRC) in cloud computing refers to a structured framework that helps organizations:
- Governance: Define policies and enforce best practices to ensure secure and efficient use of cloud resources. This includes identity and access management, cost control, and operational policies.
- Risk Management: Identify, assess, and mitigate security risks, misconfigurations, and potential breaches by implementing proactive security controls.
- Compliance: Ensure that cloud infrastructure adheres to regulatory requirements such as GDPR, HIPAA, SOC 2, and ISO 27001, and that cloud workloads meet industry standards.
AWS provides several GRC tools, including AWS Organizations, AWS Control Tower, AWS Security Hub, AWS CloudTrail, and AWS Audit Manager, to help enterprises implement a robust GRC strategy.
5. What is the Cloud Governance Structure in Cloud Service Management?
Cloud governance structure refers to the policies, roles, responsibilities, and best practices that define how cloud environments are managed and secured. It ensures that an organization maintains control over cloud resources while staying compliant with industry regulations.
A strong cloud governance structure includes:
- Identity and Access Management (IAM): Defining roles, permissions, and least-privilege access policies.
- Security Policies and Compliance Frameworks: Enforcing standards like CIS, NIST, PCI-DSS, and automated compliance monitoring.
- Resource Management and Cost Control: Implementing budget controls, cost allocation tags, and reserved capacity planning.
- Continuous Monitoring and Auditing: Using services like AWS Security Hub, AWS Config, CloudTrail, and GuardDuty to detect anomalies and maintain security posture.

- Discoverability: Developers often struggle to find existing software or services, identify their owners, and access relevant documentation. This leads to duplicated efforts and wasted time, especially in large engineering teams working across multiple applications. IDPs solve this by providing a centralized service catalog where backend, frontend, and platform engineering teams can access all infrastructure components, environments, and tools in one place.
- Self-Service: Without an IDP, developers often need to wait for DevOps teams to manually provision resources, leading to bottlenecks and delays in development cycles. IDPs introduce self-service capabilities by providing pre-configured infrastructure templates and automated workflows. For instance, instead of submitting a request for a Kubernetes cluster and waiting for DevOps to set it up, a developer can select a pre-approved cluster template and deploy it instantly through a self-service portal. This not only accelerates development but also ensures that infrastructure follows security and compliance policies without requiring manual intervention.
- Simplified Developer Experience: Managing deployments, tracking logs, and configuring services often requires developers to switch between multiple tools, leading to inefficiencies and context switching. IDPs centralize these functions into a single interface where developers can monitor deployments, manage configurations, and troubleshoot issues without needing to access multiple cloud dashboards.
What is an Internal Developer Platform?
Now that we know managing infrastructure manually slows down software development and adds extra work for DevOps teams, the next step is understanding how Internal Developer Platforms solve this problem. Instead of developers spending time provisioning compute instances, setting up networking, or fixing failed deployments, an IDP automates these tasks and provides a structured way to deploy applications.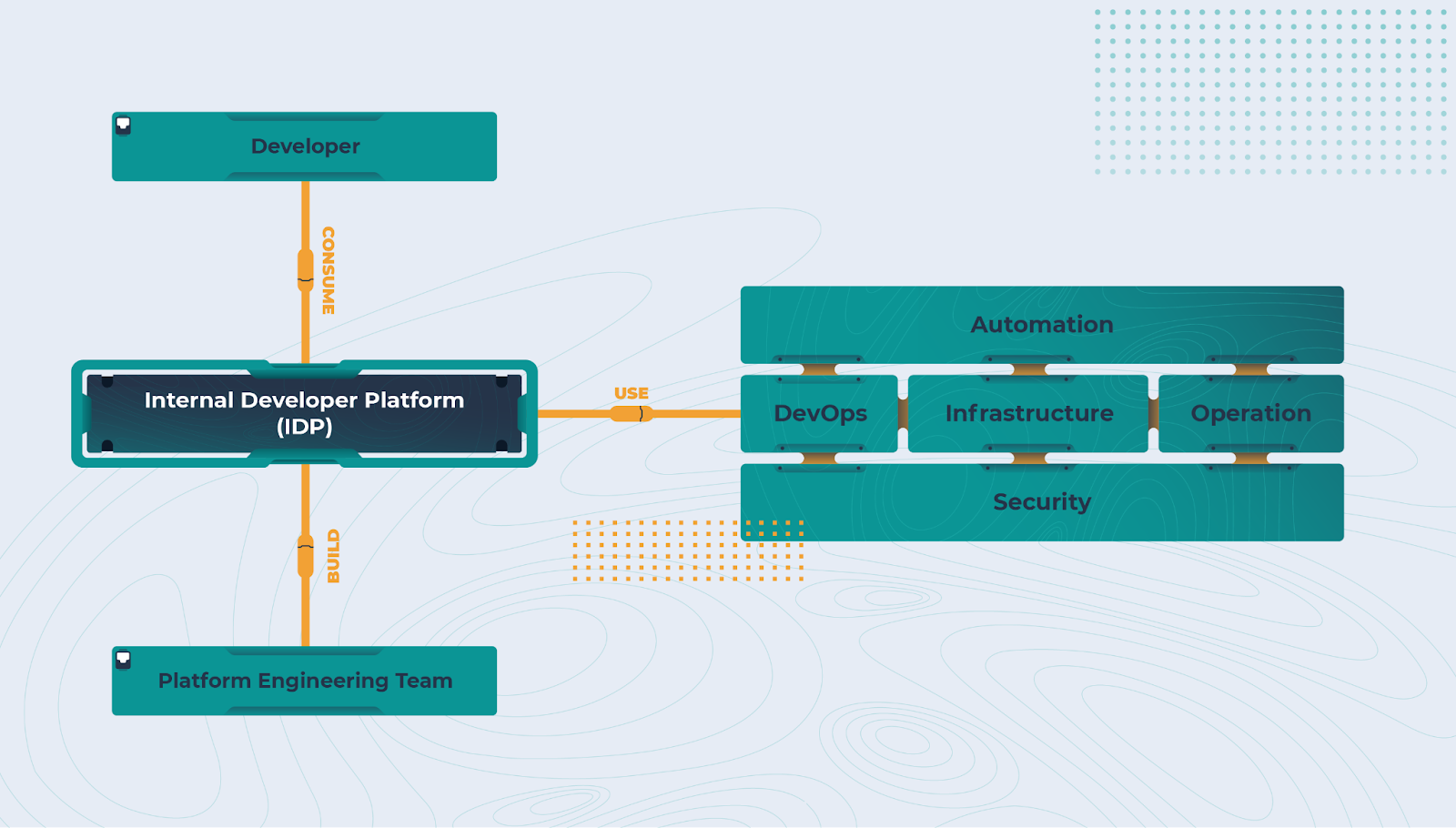 An IDP sits between developers and cloud services, handling infrastructure provisioning, security enforcement, and deployment automation. Whether it’s creating EC2 instances, managing IAM roles, or setting up Kubernetes clusters, the IDP ensures these tasks follow standardized workflows and security policies so developers don’t have to configure everything manually. If you were to build an IDP from scratch using Backstage, you would quickly realize that Backstage alone does not provide infrastructure automation. It is a framework for creating an internal developer portal, but it does not include native capabilities for provisioning infrastructure, managing CI/CD, or enforcing security policies. To turn Backstage into a fully functional IDP, you would need to integrate ArgoCD or Flux for CI/CD, Prometheus or OpenTelemetry for monitoring, and Crossplane to define CRDs and manage infrastructure as code. Even with plugins like the ArgoCD plugin, it only provides insights into deployments; it does not manage workflows independently. Beyond tooling, a custom-built IDP using Backstage would require extensive API integrations and automation to bridge gaps between different systems. Without these additions, Backstage remains a developer portal, not an IDP. Organizations that choose to build an IDP on top of Backstage must account for the time, resources, and maintenance required to manage integrations, ensure security compliance, and continuously improve the platform. In short, purpose-built IDPs offer these capabilities out of the box, reducing complexity and operational overhead.
An IDP sits between developers and cloud services, handling infrastructure provisioning, security enforcement, and deployment automation. Whether it’s creating EC2 instances, managing IAM roles, or setting up Kubernetes clusters, the IDP ensures these tasks follow standardized workflows and security policies so developers don’t have to configure everything manually. If you were to build an IDP from scratch using Backstage, you would quickly realize that Backstage alone does not provide infrastructure automation. It is a framework for creating an internal developer portal, but it does not include native capabilities for provisioning infrastructure, managing CI/CD, or enforcing security policies. To turn Backstage into a fully functional IDP, you would need to integrate ArgoCD or Flux for CI/CD, Prometheus or OpenTelemetry for monitoring, and Crossplane to define CRDs and manage infrastructure as code. Even with plugins like the ArgoCD plugin, it only provides insights into deployments; it does not manage workflows independently. Beyond tooling, a custom-built IDP using Backstage would require extensive API integrations and automation to bridge gaps between different systems. Without these additions, Backstage remains a developer portal, not an IDP. Organizations that choose to build an IDP on top of Backstage must account for the time, resources, and maintenance required to manage integrations, ensure security compliance, and continuously improve the platform. In short, purpose-built IDPs offer these capabilities out of the box, reducing complexity and operational overhead. Key Features of an IDP
Now, an IDP simplifies infrastructure management by automating provisioning, enforcing security policies, and integrating with DevOps workflows. Unlike a CI/CD pipeline that focuses only on code deployment, an IDP handles infrastructure setup, access control, and observability, making sure it is a simple development and operations process.Infrastructure as Code for Automation
Manages infrastructure through code-based templates, eliminating manual setup and ensuring consistency.- IDPs integrate with Terraform, OpenTofu, Ansible, Helm, and eventually Pulumi to automate resource provisioning. With Kubernetes as a core component, test environments can be deployed using Helm, streamlining application deployments in a structured and repeatable manner.
- Infrastructure is defined as code, ensuring consistency across deployments.
- Developers select pre-configured templates instead of writing infrastructure code from scratch.
- Version control ensures that changes can be tracked, rolled back, and audited.
CI/CD Pipelines for Deployment
Automates application builds, testing, and deployments, reducing manual work and errors.- IDPs integrate with CI/CD tools through APIs, webhooks, and plugins. They trigger pipeline executions, enforce policies, and manage infrastructure provisioning automatically.
- Code changes trigger automated build, test, and deployment pipelines.
- Developers don’t need to configure CI/CD workflows - they use pre-built templates that ensure best practices.
Role-Based Access Control for Security
Controls who can modify infrastructure and deploy applications, enforcing strict access policies.- Only authorized users can modify infrastructure or trigger deployments.
- Permissions can be set at different levels - project, service, or environment-based access.
- Security policies ensure compliance with organizational standards and industry regulations.
Why Are More Organizations Using IDPs?
Managing your cloud infrastructure isn’t as simple as spinning up an EC2 instance or deploying an application. As organizations scale, their infrastructure and environment management become more complex - multiple cloud providers, containerized applications, strict security policies, and interconnected services. Developers need fast access to resources, but setting up environments manually slows them down and increases the chances of misconfigurations. Internal Developer Platforms solve these challenges by automating infrastructure tasks and enforcing standardized workflows across the development ecosystem. Here’s why more organizations are adopting IDPs:Faster Development Cycles
Provisioning infrastructure manually can take hours or even days, depending on approval workflows and configuration steps. IDPs speed up the process by giving developers access to pre-approved infrastructure setups.- Developers can provision virtual machines, databases, and networking resources instantly instead of waiting for DevOps approvals.
- Automated CI/CD pipelines ensure applications are tested and deployed consistently.
- Pre-configured templates remove inconsistencies, making sure every environment is deployed the same way.
Lower Operational Costs
Manually handling infrastructure requests puts a heavy load on DevOps teams, increasing operational costs. IDPs automate infrastructure provisioning, allowing developers to self-serve resources without relying on any manual intervention.- Developers can deploy applications without waiting for DevOps to set up environments, reducing downtime.
- IDPs offer cost estimation tools, helping teams see expected cloud expenses before deploying resources.
- By automating infrastructure management, companies reduce the need for large DevOps teams, optimizing operational costs.
Real-World Impact of IDPs
Organizations that integrate IDPs see measurable improvements in efficiency, security and compliance standards, and cost savings.- 85% of organizations agree that investing in IDPs and improving Developer Experience (DevEx) directly contributes to revenue growth.
- 77% of companies report a significant reduction in time-to-market due to centralized tooling, standardized workflows, and automated deployments.
- IDPs help reduce redundant infrastructure tasks, allowing engineering teams to focus on high-value development instead of manual provisioning and troubleshooting.
How Different IDPs Work
There are several internal developer platform examples in the industry, each designed to simplify your infrastructure management and application deployment. Not all Internal Developer Platforms work the same way. While they share the same goal - automating infrastructure provisioning, enforcing security policies, and simplifying deployments, their approaches vary. Some IDPs focus on stack-based deployments, where platform teams define reusable infrastructure components, while others offer UI-driven infrastructure automation, providing a visual interface for developers to configure resources without writing Terraform. Other platforms take an API-first approach, integrating directly into existing DevOps workflows.Stack-based Deployments
One approach to IDPs is stack-based deployments, where infrastructure configurations are standardized and reused across multiple teams. Cycloid follows this model by allowing platform teams to define stacks for cloud services such as AWS EC2, RDS, and S3. Developers can then deploy these pre-configured stacks without worrying about networking, security groups, or storage configurations. To provide a visual representation of how Cycloid enables stack-based infrastructure management, the diagram below shows how predefined infrastructure stacks, reusable templates, and automated deployment workflows streamline infrastructure provisioning while ensuring governance, cost estimation, and policy enforcement.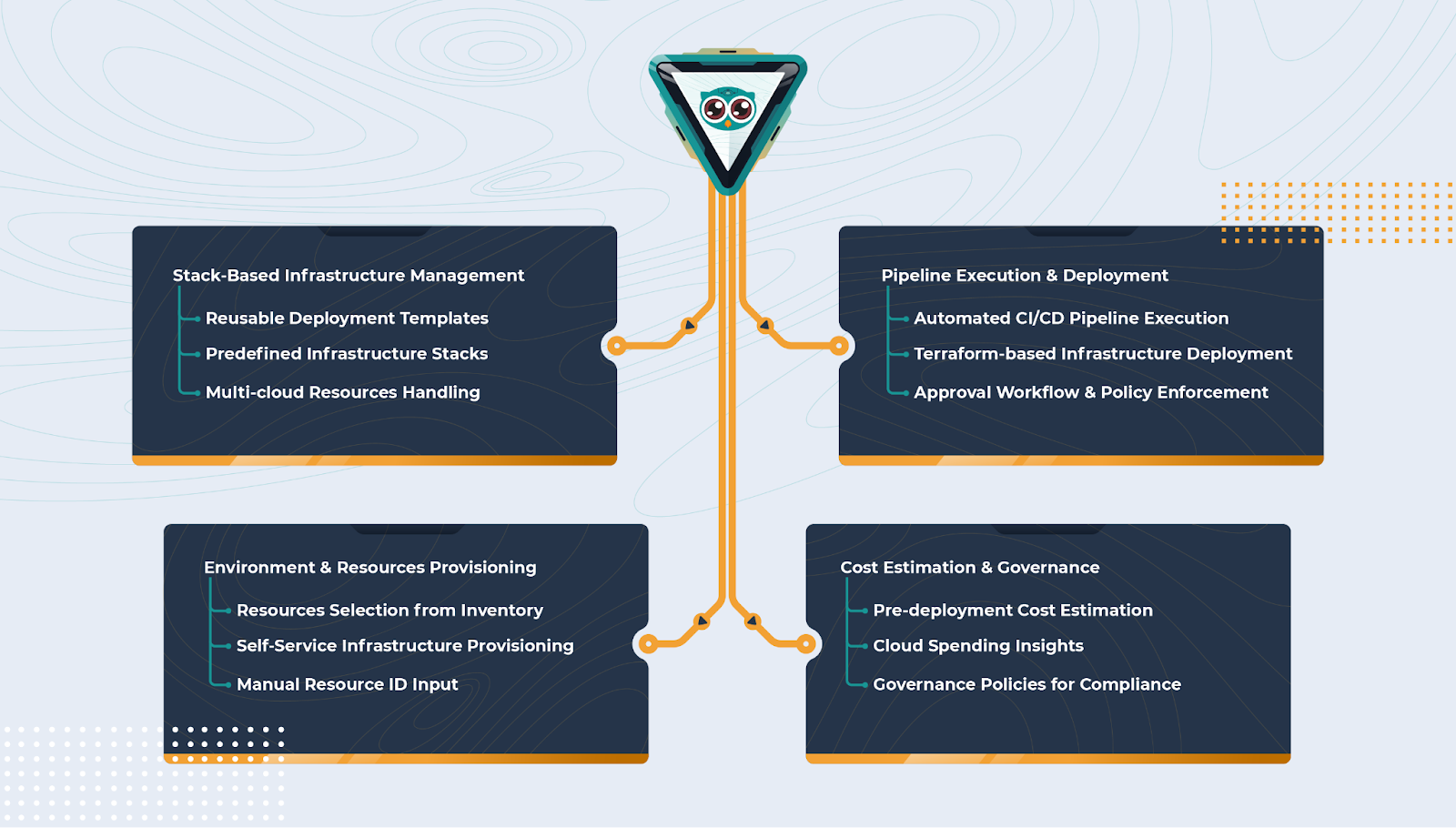 This works by using Infrastructure as Code, service catalogs, and orchestration layers:
This works by using Infrastructure as Code, service catalogs, and orchestration layers: - Pre-defined IaC Modules – Platform teams create reusable infrastructure modules using Terraform, OpenTofu, Ansible, Helm, or Pulumi, defining compute, networking, and storage configurations.
- Service Catalog & Parameterized Deployment – Developers select a predefined stack (e.g., AWS EC2 + RDS, Kubernetes cluster) from the IDP catalog, customizing parameters like instance type, VPC, and IAM roles.
- Automated Provisioning via Workflow Orchestration – The IDP invokes Terraform or Pulumi execution through an automation engine (e.g., ArgoCD, Jenkins, or a custom workflow runner), applying infrastructure changes without manual intervention.
- Built-in Policy & Security Enforcement – The IDP integrates with IAM, OPA, or custom rule engines to validate configurations, enforce RBAC, restrict unapproved changes, and ensure compliance with security standards before provisioning.
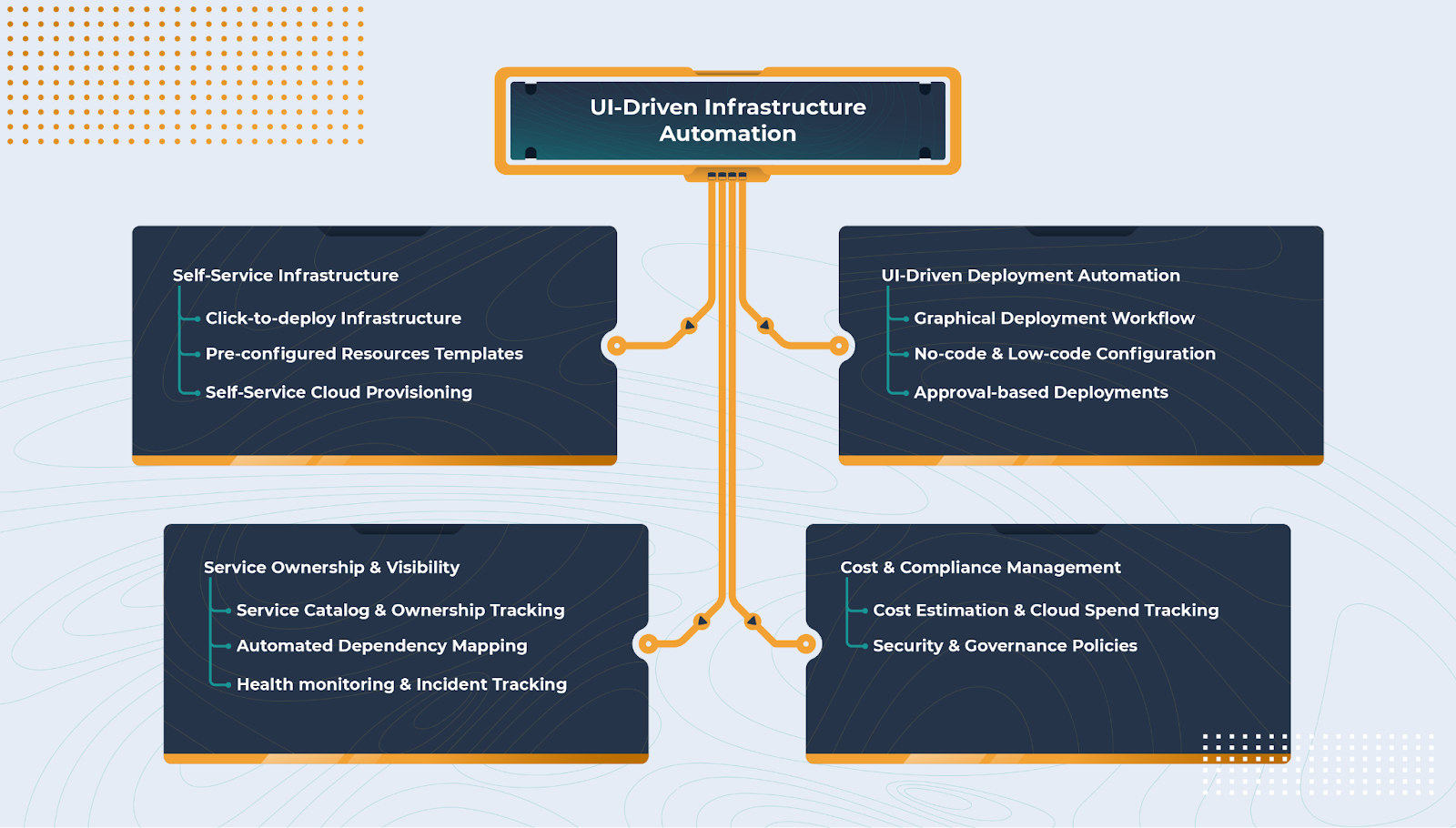
UI-driven Infrastructure Automation
Another approach is UI-driven infrastructure automation, which simplifies the provisioning process by allowing developers to select infrastructure components through an interactive interface. Instead of writing Terraform scripts or navigating complex Kubernetes configurations, developers can deploy resources with a few clicks. This model integrates with API-based automation, self-service interfaces, and cloud provisioning tools:- Visual Control Plane – Cycloid provides a web interface where users can configure cloud resources through an interactive UI instead of manually writing Infrastructure as Code configurations.
- Service Catalog & API Calls – Behind the UI, pre-configured infrastructure templates (Terraform modules, Kubernetes manifests) are stored in a service catalog.
- On-Demand Resource Provisioning – When a developer submits a request, the IDP makes API calls to cloud providers (AWS, GCP, Azure) or internal automation layers (Terraform Cloud, ArgoCD) to create infrastructure.
- Self-Service with Governance – Role-based access control makes sure that only authorized developers can provision resources, and approval workflows can be enforced if needed.
 Now, if you were to build an IDP from scratch using Backstage, several challenges would arise. While Backstage provides a framework for building an internal developer platform, it does not include infrastructure automation, security enforcement, or CI/CD management out-of-the-box. This means DevOps teams would need to integrate multiple tools and use custom plugins to make it a full-fledged IDP. Some of the limitations include:
Now, if you were to build an IDP from scratch using Backstage, several challenges would arise. While Backstage provides a framework for building an internal developer platform, it does not include infrastructure automation, security enforcement, or CI/CD management out-of-the-box. This means DevOps teams would need to integrate multiple tools and use custom plugins to make it a full-fledged IDP. Some of the limitations include: - Security & Governance Gaps – Backstage lacks built-in IAM, RBAC, and credential management, requiring custom authentication and policy enforcement integrations (e.g., OPA, Rego, or Terraform Sentinel)by default.
- Lack of CI/CD Tracking & Observability – It has no native pipeline tracking, requiring additional plugins to fetch logs from GitHub Actions, GitLab CI, or ArgoCD to monitor deployments.
- No Cost Estimation & FinOps Support – Cloud cost tracking isn't built-in, meaning teams must integrate AWS Cost Explorer, GCP Billing API, or Azure Cost Management separately.
- Manual Infrastructure Provisioning – No built-in Terraform or Kubernetes automation, requiring additional configurations and workflow automation.
Deploying an Application Using Cycloid
Cycloid easily eliminates these challenges by offering an all-in-one platform that includes stack-based infrastructure automation, security policies, observability, and cost tracking out-of-the-box. Instead of stitching together different tools, Cycloid provides a simple interface for deploying and managing your cloud infrastructure.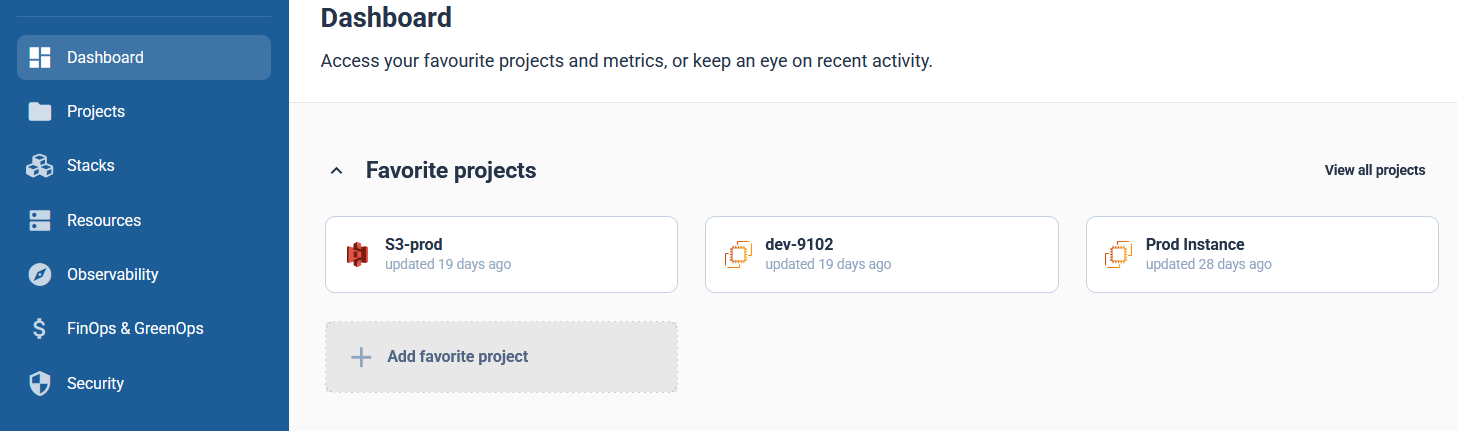 Instead of writing Terraform from scratch or configuring cloud resources manually, developers can use pre-configured stacks to provision environments, define resources, estimate costs, and deploy applications, all through an automated workflow. The first step in this process is creating a stack. A stack in Cycloid defines the infrastructure resource that will be deployed, such as an AWS EC2 instance, an RDS database, or a Kubernetes cluster.
Instead of writing Terraform from scratch or configuring cloud resources manually, developers can use pre-configured stacks to provision environments, define resources, estimate costs, and deploy applications, all through an automated workflow. The first step in this process is creating a stack. A stack in Cycloid defines the infrastructure resource that will be deployed, such as an AWS EC2 instance, an RDS database, or a Kubernetes cluster. 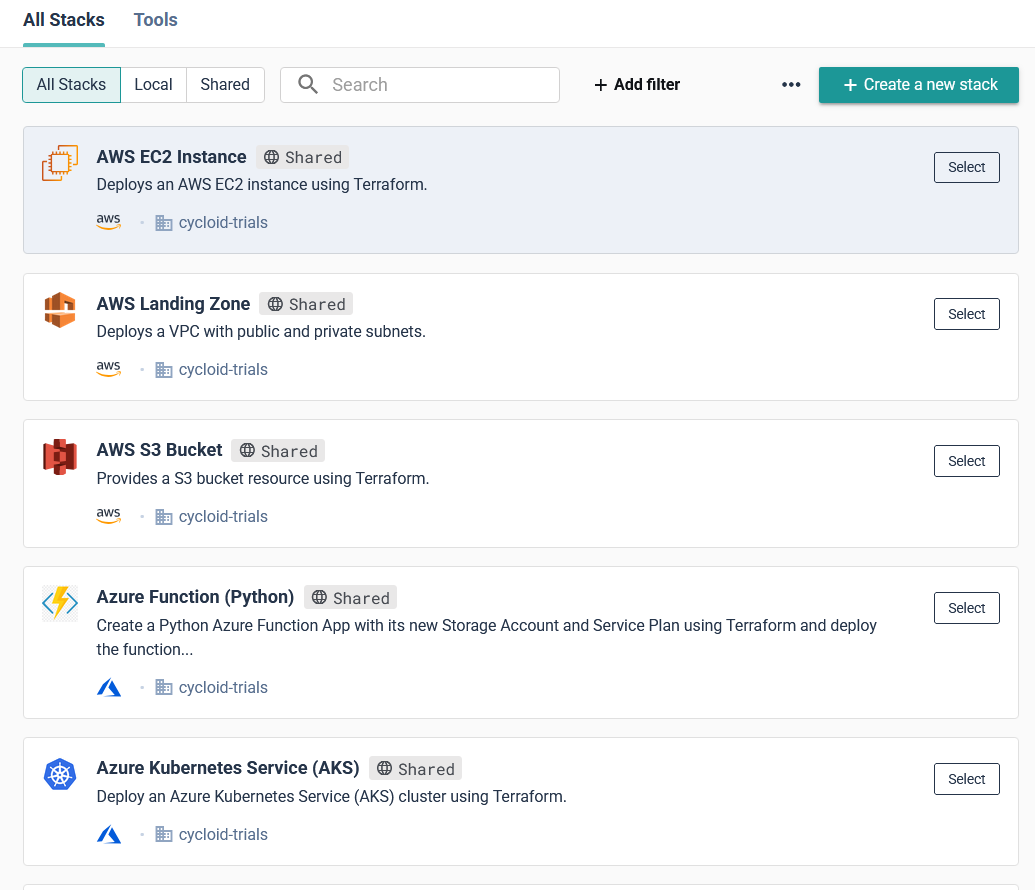 This ensures consistency across deployments for development and operations teams and eliminates the need for developers to manage infrastructure configurations manually. By selecting a predefined stack, teams can enforce security policies, optimize resource allocation, and reduce the risk of misconfigurations. Once the stack is created, the next step is to set up a project. In the upcoming update to Cycloid, a project will serve as the top-level structure where teams can organize deployments more flexibly. Instead of a direct project-to-stack mapping, Cycloid is introducing a component layer, allowing teams to create a project, then define environments such as production or staging, and finally, components within those environments. Each component will utilize a stack, making it possible to compose an application project in an environment using multiple stacks. This enhancement provides greater modularity, enabling teams to manage infrastructure and applications more efficiently while maintaining clear separation between environments and services.
This ensures consistency across deployments for development and operations teams and eliminates the need for developers to manage infrastructure configurations manually. By selecting a predefined stack, teams can enforce security policies, optimize resource allocation, and reduce the risk of misconfigurations. Once the stack is created, the next step is to set up a project. In the upcoming update to Cycloid, a project will serve as the top-level structure where teams can organize deployments more flexibly. Instead of a direct project-to-stack mapping, Cycloid is introducing a component layer, allowing teams to create a project, then define environments such as production or staging, and finally, components within those environments. Each component will utilize a stack, making it possible to compose an application project in an environment using multiple stacks. This enhancement provides greater modularity, enabling teams to manage infrastructure and applications more efficiently while maintaining clear separation between environments and services.  The diagram below shows how Cycloid structures deployments with its new component layer. It highlights how projects, environments, and components are organized, with each component leveraging a stack to automate infrastructure provisioning and deployment. This model ensures flexibility by allowing applications to be composed across multiple stacks while maintaining a GitOps-based approach for consistency and governance.
The diagram below shows how Cycloid structures deployments with its new component layer. It highlights how projects, environments, and components are organized, with each component leveraging a stack to automate infrastructure provisioning and deployment. This model ensures flexibility by allowing applications to be composed across multiple stacks while maintaining a GitOps-based approach for consistency and governance. 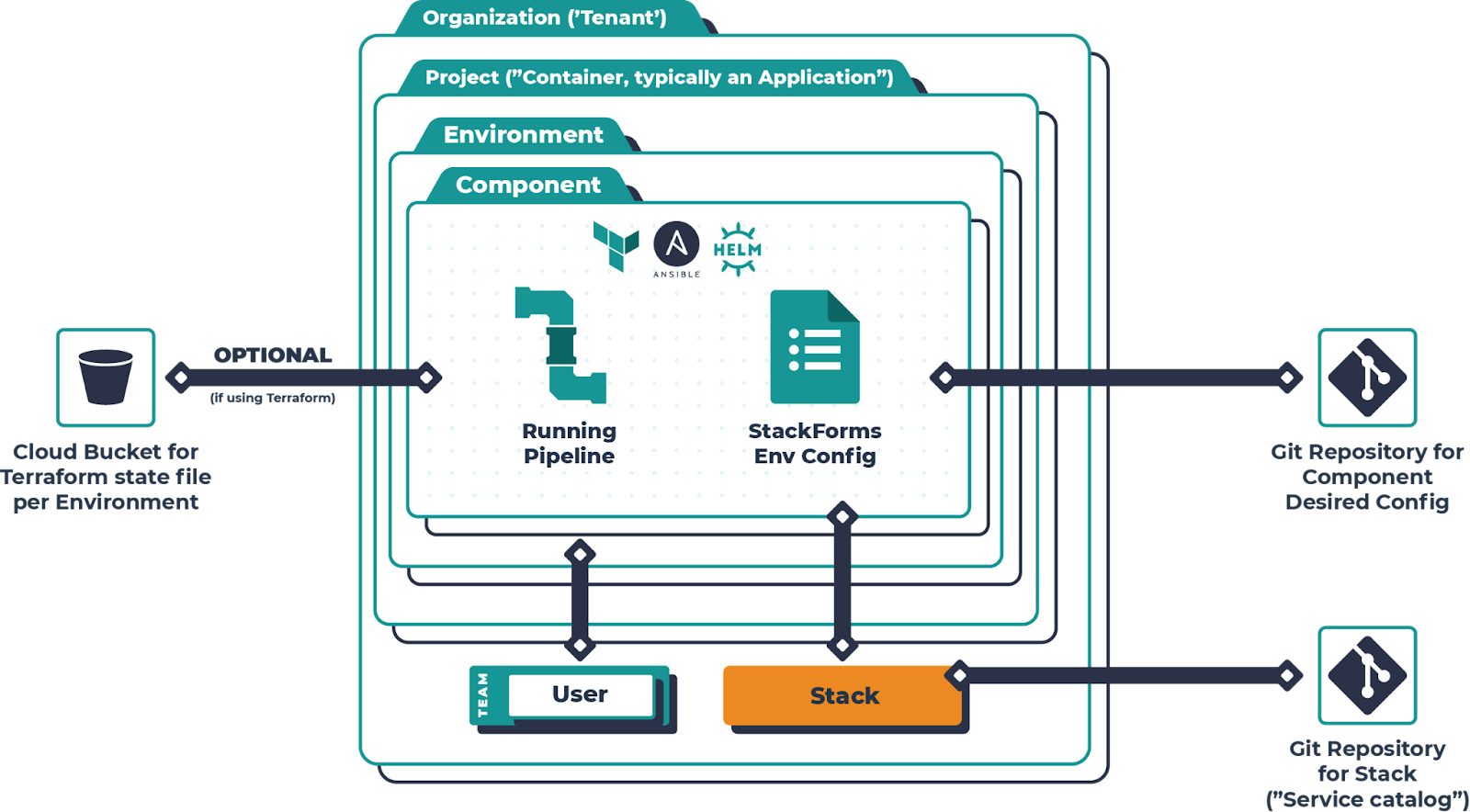 Now, developers assign security teams together, configure access permissions, and define environment configurations within the project. Instead of handling networking, IAM roles, or security groups separately, the project inherits these configurations from the stack, making sure that every deployment follows the same standards.
Now, developers assign security teams together, configure access permissions, and define environment configurations within the project. Instead of handling networking, IAM roles, or security groups separately, the project inherits these configurations from the stack, making sure that every deployment follows the same standards. 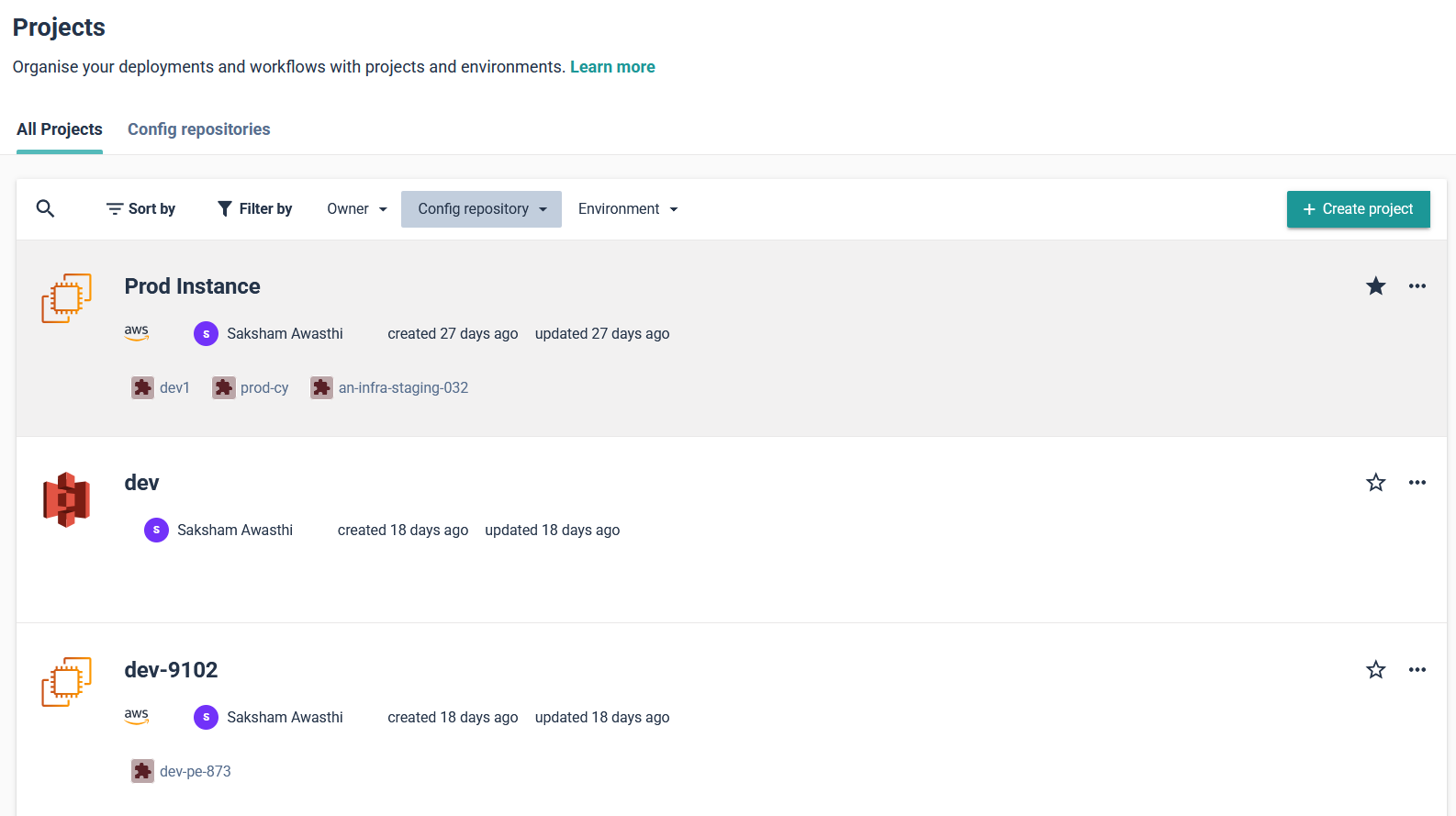 With the project in place, developers can move on to setting up an environment. In the upcoming update to Cycloid, an environment (such as production or staging) will act as a structured layer within a project, where applications and infrastructure components are organized. Instead of binding an environment directly to a single stack, Cycloid's new component layer will allow teams to define multiple components within an environment, each utilizing different stacks. This enhancement enables greater flexibility in managing infrastructure, making it possible to compose an application using several stacks within the same environment.
With the project in place, developers can move on to setting up an environment. In the upcoming update to Cycloid, an environment (such as production or staging) will act as a structured layer within a project, where applications and infrastructure components are organized. Instead of binding an environment directly to a single stack, Cycloid's new component layer will allow teams to define multiple components within an environment, each utilizing different stacks. This enhancement enables greater flexibility in managing infrastructure, making it possible to compose an application using several stacks within the same environment. 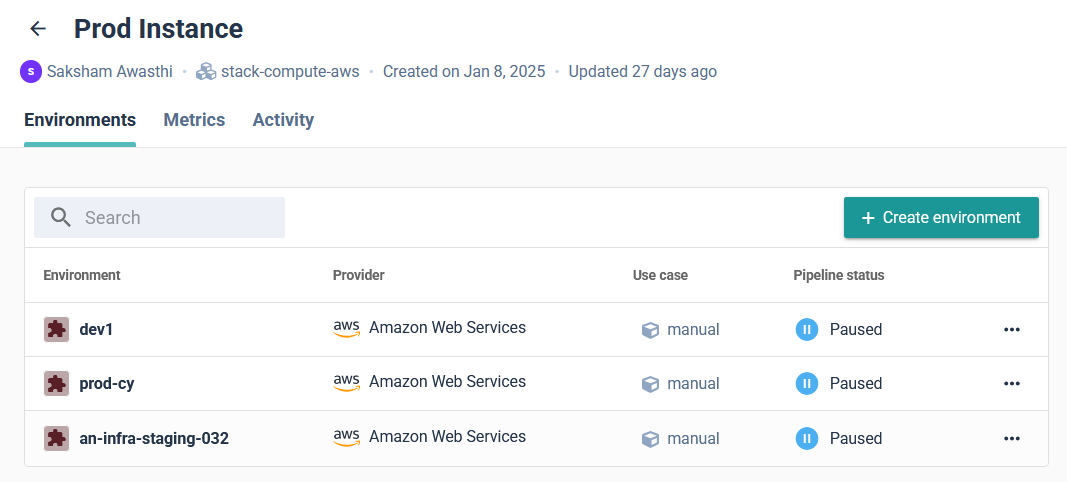 When creating an environment, teams typically define its cloud provider and infrastructure setup based on the project's requirements. With Cycloid’s upcoming component layer, environments can include multiple components, each leveraging different stacks to support various services within the same environment. This allows teams to flexibly compose applications across multiple cloud providers or infrastructure setups as needed.
When creating an environment, teams typically define its cloud provider and infrastructure setup based on the project's requirements. With Cycloid’s upcoming component layer, environments can include multiple components, each leveraging different stacks to support various services within the same environment. This allows teams to flexibly compose applications across multiple cloud providers or infrastructure setups as needed.  This flexibility makes sure that existing cloud resources can be reused while maintaining the option to define custom configurations when required. Cycloid automates Terraform execution, provisioning the required infrastructure without requiring developers to apply configurations manually. Cycloid handles everything from instance creation to networking and IAM role assignment, making deployments faster and error-free. Once the infrastructure is provisioned, the CI/CD pipeline takes over. Cycloid follows a GitOps-based approach, where all desired configurations are version-controlled in a Git repository, which serves as the source of truth for infrastructure and application deployments. Cycloid integrates automated pipelines that fetch Terraform configurations, validate infrastructure changes, and ensure deployments remain consistent with the declared state in Git. This ensures that every modification is auditable, reproducible, and aligned with the defined infrastructure state. To ensure clear visibility into deployments, Cycloid provides an Observability Dashboard that gives teams a real-time view of active, paused, and failed pipeline runs. This helps developers track Terraform execution, identify issues in their deployment process, and troubleshoot errors without switching between cloud provider dashboards. By structuring deployments through stacks, projects, environments, and components, Cycloid’s IDP ensures that infrastructure provisioning is consistent, automated, and easily accessible to developers. This approach eliminates the complexity of manual setups, reduces DevOps workload, and accelerates application delivery. To explore Cycloid more as an IDP, refer to the documentation.
This flexibility makes sure that existing cloud resources can be reused while maintaining the option to define custom configurations when required. Cycloid automates Terraform execution, provisioning the required infrastructure without requiring developers to apply configurations manually. Cycloid handles everything from instance creation to networking and IAM role assignment, making deployments faster and error-free. Once the infrastructure is provisioned, the CI/CD pipeline takes over. Cycloid follows a GitOps-based approach, where all desired configurations are version-controlled in a Git repository, which serves as the source of truth for infrastructure and application deployments. Cycloid integrates automated pipelines that fetch Terraform configurations, validate infrastructure changes, and ensure deployments remain consistent with the declared state in Git. This ensures that every modification is auditable, reproducible, and aligned with the defined infrastructure state. To ensure clear visibility into deployments, Cycloid provides an Observability Dashboard that gives teams a real-time view of active, paused, and failed pipeline runs. This helps developers track Terraform execution, identify issues in their deployment process, and troubleshoot errors without switching between cloud provider dashboards. By structuring deployments through stacks, projects, environments, and components, Cycloid’s IDP ensures that infrastructure provisioning is consistent, automated, and easily accessible to developers. This approach eliminates the complexity of manual setups, reduces DevOps workload, and accelerates application delivery. To explore Cycloid more as an IDP, refer to the documentation. Conclusion
So far, we’ve seen how an IDP internal developer platform removes the complexity of delivering software and managing infrastructure. We explored different IDP models and how Cycloid’s stack-based approach allows developers to deploy applications without handling Terraform or cloud configurations manually. With an IDP in place, teams can ship code faster while keeping infrastructure secure and consistent.Frequently Asked Questions
1. What is the Difference Between a Developer Platform and a Developer Portal?
A developer platform provides tools, automation, and infrastructure for building, deploying, and managing applications, while a developer portal is a centralized interface where developers can access tools, documentation, APIs, and internal services.2. What is the Difference Between an Internal Developer Platform and a Devops Platform?
An Internal Developer Platform (IDP) automates infrastructure provisioning and abstracts complexity for developers, while a DevOps platform focuses on CI/CD, collaboration, and automating the software development lifecycle.3. What is an IDP Platform Used for?
An IDP simplifies infrastructure management by automating resource provisioning, enforcing security policies, and providing self-service deployment capabilities for developers.4. What is the Difference Between an Internal Developer Platform and a Service Catalog?
An IDP automates infrastructure and integrates CI/CD workflows, while a service catalog provides a collection of pre-approved services that developers can request and deploy....
Imagine you’re a DevOps engineer managing microservices on AWS. How would you configure auto-scaling to handle high traffic without wasting any resources?
Your teammate is setting up an auto-scaling policy using Terraform. The goal is to automatically add more EC2 instances when CPU usage gets too high so the application can handle more API requests during peak traffic.
However, there is a mistake in the Terraform configuration; the CPU utilization threshold is set to 10% instead of a higher, more reasonable value, like 60-70%. Because of this, even small activities like health checks and background tasks trigger auto-scaling. As a result, the system keeps launching new EC2 instances unnecessarily, even when they are not needed.
By the end of the month, the organization is hit with an unexpected bill of $18,000. The mistake was small, but its impact was significant.
This kind of problem is common in organizations where multiple teams manage their own resources independently. The data team, led by a data platform engineer, is responsible for managing large-scale data processing using Amazon EMR and analytics workloads on Amazon Redshift. These engineers ensure that data infrastructure scales efficiently without incurring excessive costs.
The infrastructure team manages networking resources such as VPCs, subnets, and security groups, ensuring connectivity and security across all environments. The application team deploys microservices using Amazon ECS or EKS, running workloads on EC2 instances or Fargate. Meanwhile, the ML team might use Amazon SageMaker with GPU-powered instances for training models.
Without a centralized system to track and manage these resources, misconfigurations, such as over-provisioning, idle instances, or conflicting configurations, can easily go unnoticed. When different teams work separately without a shared system, unexpected cost spikes are more likely.
When cloud costs increase unexpectedly, it indicates inefficiencies in how resources are configured and managed within your organization. Resolving these issues requires more than just cost tracking. It needs an approach where resource provisioning, scaling, and cost management are closely aligned and built into the infrastructure setup.
Platform engineering philosophy is the practice of building and maintaining an internal developer platform that acts as a bridge between developers and the underlying cloud infrastructure. It provides a structured system where cost management, resource provisioning, and scaling are built into daily workflows. This makes sure that resources are used efficiently, scaling is handled correctly, and cloud expenses stay within the organization’s budget.
Platform Engineering vs DevOps
Before diving into the differences, let's first address the question: What is platform engineering? Platform engineering is the practice of building and maintaining an internal developer platform that acts as a bridge between developers and the underlying cloud infrastructure.
Now, scaling your cloud resources efficiently and keeping the cloud costs under control at the same time are some of the major challenges for many organizations. Mismanaged resources, misconfigurations, and the absence of centralized monitoring often lead to some unnecessary expenses. To address such issues, it is important to understand how platform engineering philosophy and DevOps differ in their approach.
Now, here is a comparison table of platform engineering philosophy and DevOps, focusing on their roles in resource management and cost optimization:
Platform engineering is all about building a shared system that simplifies how DevOps or Infrastructure teams manage their infrastructure and control cloud costs. Standardizing processes and enforcing clear rules helps reduce errors and makes sure that resources within your infrastructure are used effectively.
On the other hand, DevOps focuses more on teamwork and flexibility. It improves team collaboration and speeds up the deployments as well, but this flexibility can sometimes lead to inconsistent practices and higher cloud costs.
For organizations struggling with increasing cloud expenses and resource inefficiencies, combining platform engineering with DevOps can strike the right balance. It brings structure to resource management while still allowing teams to work efficiently.
How Does Infrastructure Platform Engineering Philosophy Help in Cost Management?
Now as we know the differences between platform engineering and DevOps, it’s clear that platform engineering takes a more structured approach for managing your cloud infrastructure. This philosophy is particularly effective in addressing cloud cost challenges by integrating cost management directly into resource provisioning, scaling, and governance processes.
Standardizing Resource Provisioning
One of the main reasons for higher cloud costs is allocating resources without proper planning or provisioning instances that are larger than necessary. For example, using an EC2 instance like m5.4xlarge instead of m5.large increases your cloud expenses without matching the actual needs of the application. Similarly, not setting up lifecycle policies for S3 buckets can lead to unused data, such as old logs or temporary files, being stored for long periods, which can also add up to storage costs.
These modules define how resources should be configured, including instance sizes, network configurations, and tags. Since they are created by a central or platform team, they ensure that all considerations, such as performance, cost efficiency, and security are accounted for before provisioning. For example, an EC2 module can guide teams to select an instance size that fits both the application’s needs and the organization’s budget at the same time. It can also include tagging rules to track spending and identify resources that are no longer needed within your infrastructure. By using these modules, teams can avoid over-provisioning and configure their resources correctly.
Automating Scaling
Next, let’s talk about scaling, one of the trickiest parts of managing cloud infrastructure. We’ve all been there; when setting up a new EC2 instance or Kubernetes cluster, there’s always some guesswork involved. To be safe, we often over-provision and end up paying for idle resources, or we under-provision and run into performance issues. When scaling isn’t properly configured, extra instances may be added during high traffic but don’t scale down when demand drops, leading to unnecessary costs.
Platform engineering helps by automating scaling based on real-time usage. Instead of relying on fixed thresholds or manual adjustments, scaling policies automatically adjust resources based on actual workload demands. For example, EC2 instances can be set to scale up when CPU usage goes above 70% and scale down when it drops below 30%. Kubernetes clusters can scale pods based on memory usage or request load, ensuring resources are always in line with demand.
By integrating these automated scaling policies, resources are provisioned only when needed and removed as soon as traffic decreases. This enables self-service capabilities, allowing development teams to deploy applications without worrying about over-provisioning or unexpected costs. Instead of manually adjusting scaling settings, teams can rely on predefined rules set by the platform engineering team, ensuring resources are used efficiently.
Enforcing Policies
Now, let’s look at policy enforcement, which plays an important role in controlling cloud costs. When teams create resources without following standard rules, tracking expenses and optimizing usage becomes much harder. For example, if EC2 instances and S3 buckets are not tagged properly, it becomes difficult to determine which project, cost center, or team owns them. As a result, unused instances may keep running unnoticed, adding to cloud costs without anyone being accountable for them.
Platform engineering philosophy addresses this by enforcing governance policies that define how resources should be created, monitored, and destroyed. These policies require teams to follow some specific rules, such as applying cost allocation tags, setting spending limits, and restricting certain instance types. For example, an organization might enforce a rule where every EC2 instance must have tags like Project: BillingSystem, Owner: DevOpsTeam, and Environment: Production to improve cost monitoring. Another policy could prevent the provisioning of high-cost instances like r5.8xlarge unless explicitly approved.
By integrating these policies into the platform, organizations establish pre-defined rules that everyone in the team must follow. This makes sure that cost control is part of daily operations, prevents unnecessary spending, simplifies audits, and keeps cloud costs within the organization's budget.
Organizations use various platform engineering tools to enforce policies and manage cloud resources efficiently. Tools like Backstage, Crossplane, and Firefly help standardize provisioning, enforce cost controls, and provide self-service capabilities for developers.
Setting Up Monitoring for Cloud Costs (Hands-On)
Now that we have seen how platform engineering philosophy helps control your cloud costs through provisioning, scaling, and policy enforcement, the next step in the list is monitoring your cloud costs. Without proper cost monitoring, unexpected expenses can build up and go unnoticed until they appear in your billing report.
To prevent this, we will set up an automated cost monitoring system using Terraform, AWS Budgets, and AWS Cost Explorer. This setup will help you track your cloud spending, send alerts when costs exceed a defined threshold, and provide insights into which resources contribute the most to the overall bill.
To track costs, we first need to create some AWS resources. We will provision an EC2 instance and an S3 bucket using Terraform. The EC2 instance will be a t2.micro running in us-east-1, and the S3 bucket will be private. These resources will be tagged with relevant metadata such as Name, Environment, and Owner to help track expenses in AWS Cost Explorer. The following Terraform configuration provisions these resources.
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "monitoring_ec2" {
ami = "ami-0e86e20dae9224db8"
instance_type = "t2.micro"
subnet_id = "subnet-02efa144df0a77c13"
tags = {
Name = "monitoring-ec2"
Environment = "dev"
Owner = "team-a"
}
}
resource "aws_s3_bucket" "monitoring_bucket" {
bucket = "cost-monitoring-bucket-cycloid-93829"
acl = "private"
tags = {
Name = "monitoring-s3-bucket"
Environment = "dev"
Owner = "team-a"
}
}
Once the Terraform configuration is ready, we need to initialize Terraform to download the necessary provider plugins. Running the terraform init command will set up the working directory for Terraform.
At this point, Terraform will initialize the AWS provider, ensuring that all required dependencies are installed.
After initializing Terraform, we should verify what changes will be applied by running the terraform plan command. This helps confirm that Terraform will create the correct resources before actually deploying them.
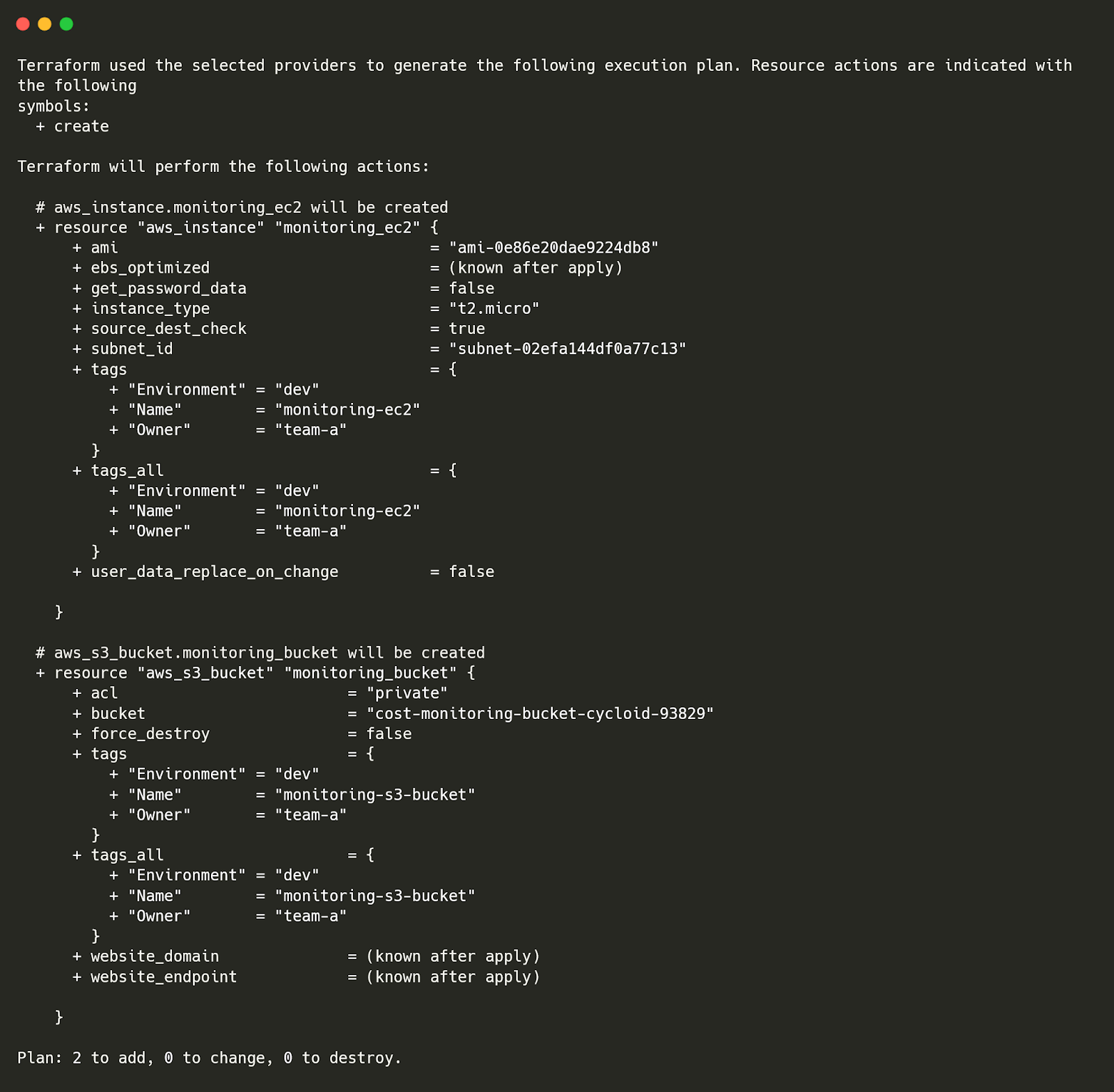
Once the plan is reviewed, we can proceed with applying the configuration. Running the terraform apply command will create the EC2 instance and S3 bucket as defined in the Terraform configuration.
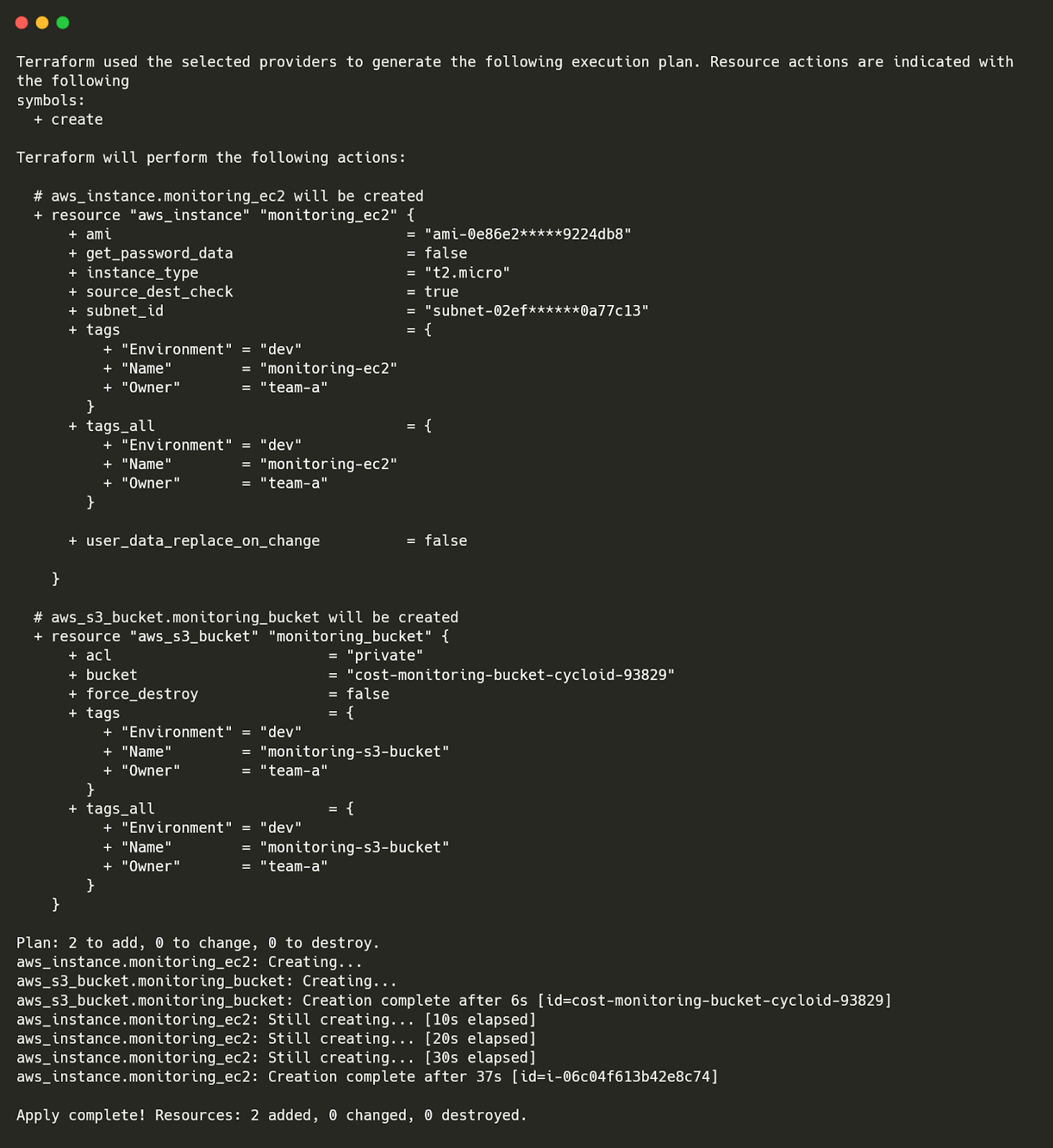
Now that the EC2 instance and S3 bucket are deployed, the next step is to create a budget to track cloud costs. Here, we will define a monthly budget of $1 and enable cost tracking. This will allow us to detect any unexpected costs early and take action before they increase further. The following Terraform configuration sets up the AWS Budgets resource.
resource "aws_budgets_budget" "monthly_cost_budget" {
name = "monthly-cost-budget"
budget_type = "COST"
limit_amount = "1"
limit_unit = "USD"
time_unit = "MONTHLY"
cost_types {
include_credit = false
include_discount = true
include_other_subscription = true
include_recurring = true
include_tax = true
}
}
Before applying this configuration, we verify it by running the terraform plan command.
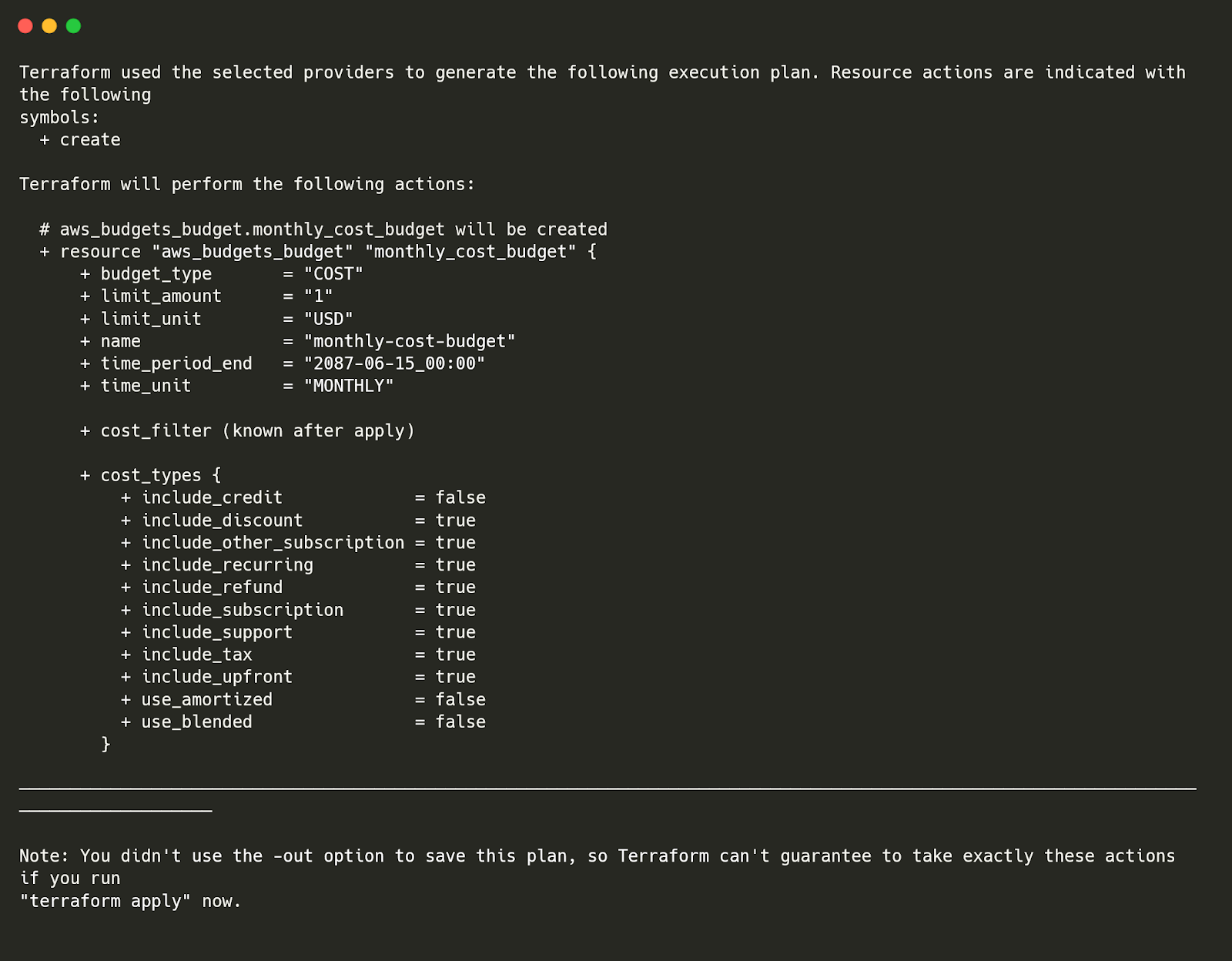
Once verified, apply the changes with the terraform apply command to create the budget in AWS. Terraform will now deploy the budget, making it visible in the AWS Budgets console.
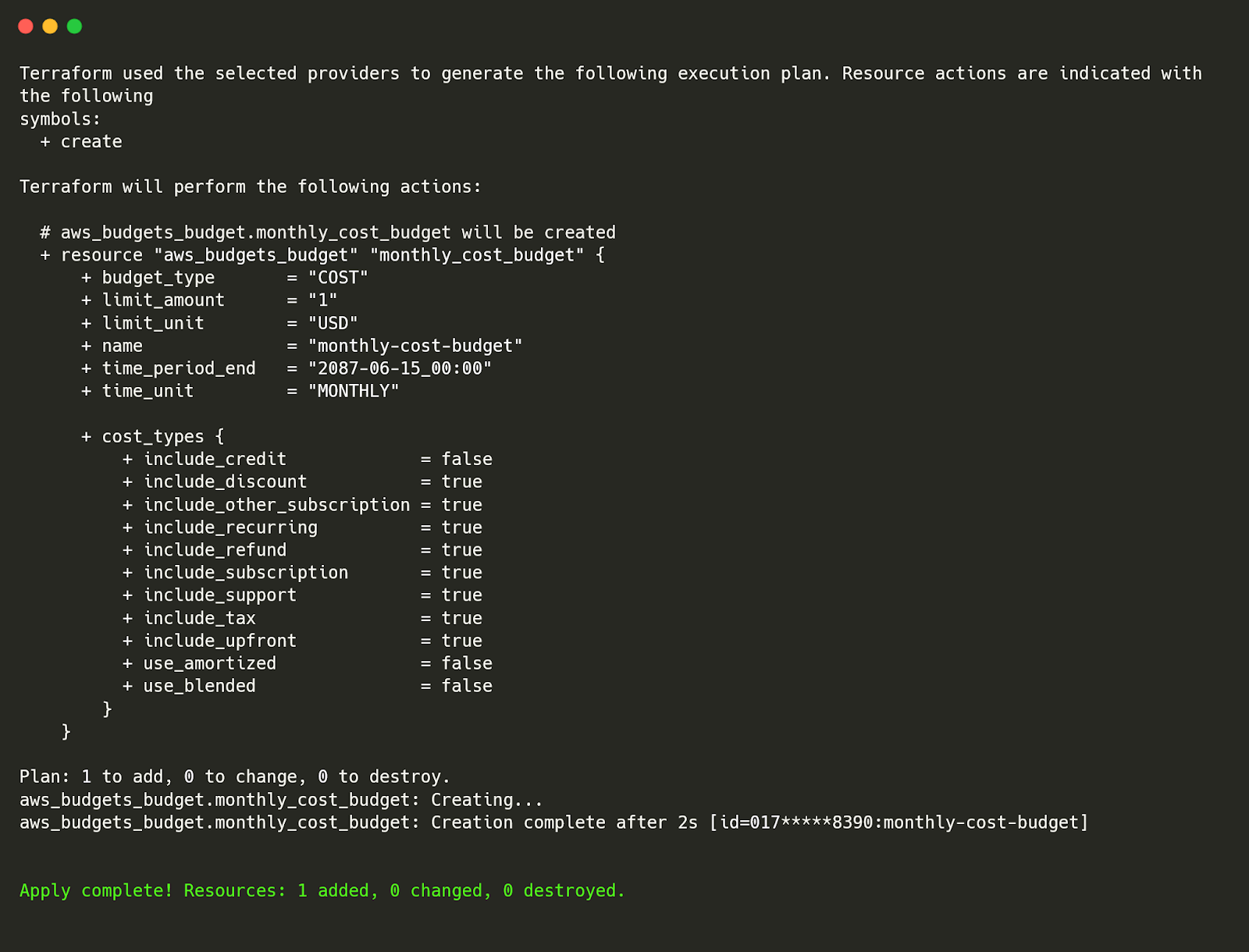
Now, having a budget in place is useful, but we also need a way to get notified when spending reaches a certain threshold. Instead of checking the budget through the AWS console, we can set up an email alert that will notify us when expenses exceed 80% of the budget. This makes sure that any unexpected charges are detected early. The following Terraform configuration creates an AWS Budget Action that sends an email alert when spending goes above 80% of the budget.
resource "aws_budgets_budget_action" "email_alert" {
budget_name = aws_budgets_budget.monthly_cost_budget.name
action_type = "NOTIFICATION"
notification {
notification_type = "ACTUAL"
comparison_operator = "GREATER_THAN"
threshold = 80.0
threshold_type = "PERCENTAGE"
subscriber {
subscription_type = "EMAIL"
address = "saksham@infrasity.com"
}
}
}
Run the terraform apply command to apply the changes and activate the budget alert.
Once the budget is created, AWS will start tracking costs, and if the spending exceeds 80% of the defined limit, an email notification will be sent to the configured address. Below is an example of an AWS Budgets alert showing that the actual cost has exceeded the set threshold.
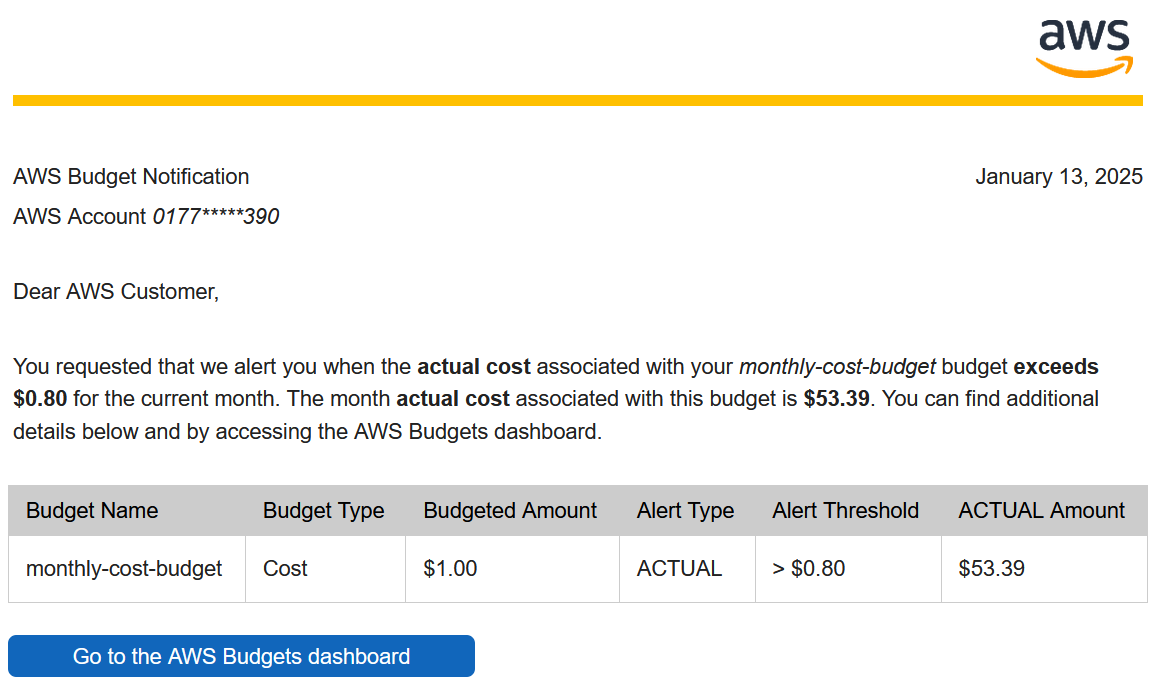
With AWS Budgets and alerts in place, cost tracking becomes automated, making sure that responsible teams are notified when spending exceeds the set limit. Without this setup, unexpected charges could easily go unnoticed until the billing cycle ends.
Best Practices for Sustainable Cloud Cost Management
Now that we have a system in place to monitor our cloud costs, the next step is making sure that cloud costs remain optimized over time as well. Just having budgets and alerts is not enough; organizations need to follow some best practices to prevent unnecessary spending and improve long-term cost efficiency.
Conduct Regular Cost Audits
Cloud environments scale over time as teams provision new resources. Without regular audits, unused or oversized instances, idle storage, and misconfigured services can lead to unnecessary cloud costs. Reviewing cloud spending every month or week helps identify such resources. For example, an audit might reveal EC2 instances running 24/7 when they are only needed during business hours. Switching such instances to a scheduled start/stop policy or using spot instances can significantly reduce expenses.
Enforce Strict Resource Tagging Policies
When multiple teams work in the same cloud environment, tracking which resources belong to which project becomes difficult. Without proper resource tagging, identifying and decommissioning unused resources becomes difficult. Enforcing a tagging policy that includes attributes like Project, Environment, and Owner ensures clear cost allocation. Using Terraform modules that require tags at the time of provisioning helps enforce this consistently across the organization.
Implement Cost Alerts and Budgets
Setting up cost alerts prevents unexpected charges by notifying teams when spending exceeds predefined limits. AWS Budgets, as configured earlier, help track total cloud costs, but organizations can extend this to monitor specific services like RDS, Lambda, and EBS snapshots. Alerts can also detect sudden spikes in usage, helping teams investigate and address cost irregularities before they become a significant issue.
By following these best practices, organizations can maintain better control over their cloud expenses. Conducting regular audits, enforcing tagging policies, and setting up cost alerts ensure cloud costs remain predictable and aligned with business needs. When combined with platform engineering principles, these measures create a sustainable approach to managing cloud costs at scale.
Now, in the earlier hands-on setup, we created an AWS budget to track cloud costs, but there were some limitations to it as well. The budget only starts tracking after the resources are deployed, and alerts are triggered only after the threshold is exceeded. This means there is no way to see the cost impact before provisioning a resource. If a large instance type like m5.4xlarge is selected instead of a smaller one, there is no immediate breakdown to show how much the cost will increase. Without visibility into expected costs upfront, most of the teams risk deploying oversized resources and only realizing the impact when the budget alert is triggered.
For more ways to reduce cloud costs, check out this blog on Cloud Cost Optimization.
Using Cycloid to Estimate and Manage Cloud Costs
This is where Cycloid simplifies cloud cost management by integrating cost estimation directly into the resource provisioning workflow. Instead of manually setting budgets, navigating Cost Explorer, and provisioning resources through Terraform, Cycloid provides everything in one place.
Before Cycloid, teams had to set up cost controls manually, define budgets, configure alerts, and provision resources from scratch with a lot of guesswork. It was easy to over-provision, miss cost spikes, or struggle with fragmented tracking across multiple tools. What if there was a centralized platform that handled all of this automatically? Cycloid simplifies cloud cost management by integrating cost estimation directly into the resource provisioning workflow. Instead of manually setting budgets, navigating Cost Explorer, and provisioning resources through Terraform, Cycloid provides everything in one place, ensuring that cost visibility and control are built into the process from the start.
Cycloid centralizes infrastructure management, allowing teams to organize deployments under structured projects and environments.
Once inside a project, Cycloid allows users to define cloud configurations without writing Terraform configurations. Teams can specify the AWS account, region, VPC ID, SSH key, and instance type through a UI-driven approach, ensuring consistency across deployments.
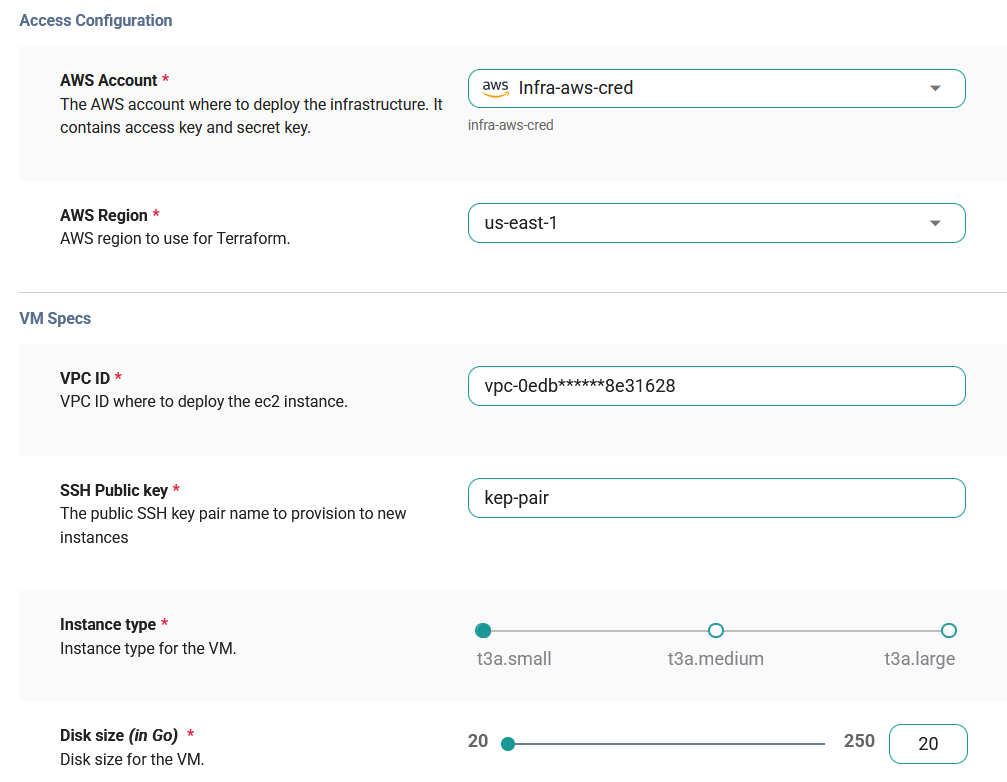
What sets Cycloid apart is its side-by-side cost estimation during resource creation. Unlike AWS Budgets, which tracks expenses after deployment, Cycloid provides real-time cost visibility before provisioning. This helps teams adjust configurations early to prevent unnecessary expenses.
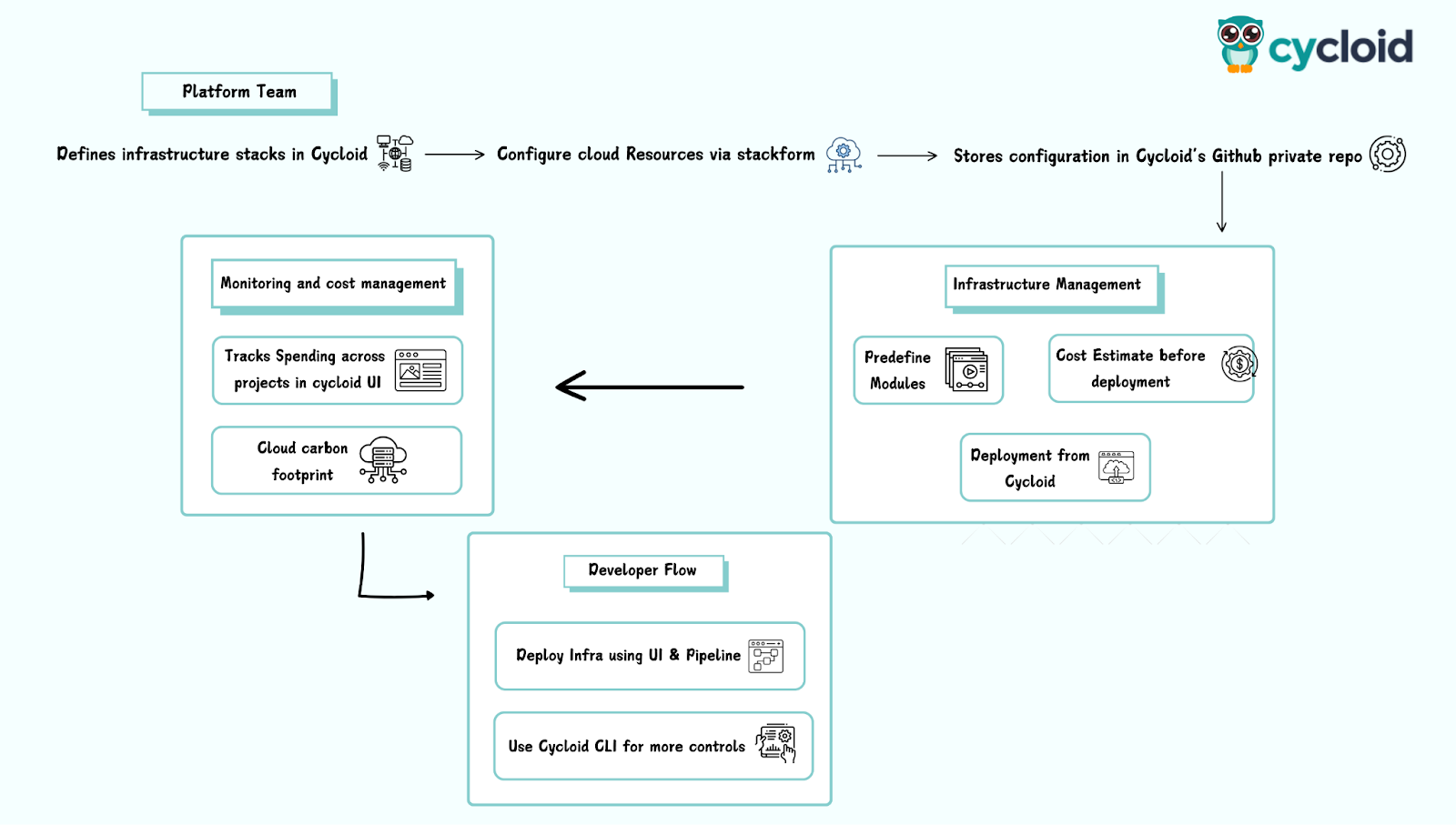
The platform team defines infrastructure stacks in Cycloid, ensuring consistency across environments. These configurations are stored in Cycloid’s GitHub private repository and can be deployed using predefined modules via the UI.
Cycloid’s stack pipeline runs Terraform with built-in governance, making sure that infrastructure deployments follow predefined policies. This means that teams don’t have to manually enforce security rules, cost limits, or instance configurations; everything is checked automatically before provisioning. The pipeline applies standard practices for instance sizing, network configurations, and tagging, reducing misconfigurations and ensuring compliance across all the environments.
Developers can use Cycloid’s pipeline-driven workflow to deploy infrastructure directly without writing Terraform configurations. The UI provides cost estimates before deployment, and teams can track spending across projects in Cycloid’s dashboard.
Cycloid also offers additional features like cloud carbon footprint tracking and deeper cost visibility to help organizations maintain sustainable and optimized cloud spending.
Once the configurations are set, Cycloid automatically runs a pipeline to deploy the infrastructure. It pulls the Terraform stack, executes a terraform plan step to generate an execution plan, and then applies the changes to provision resources.
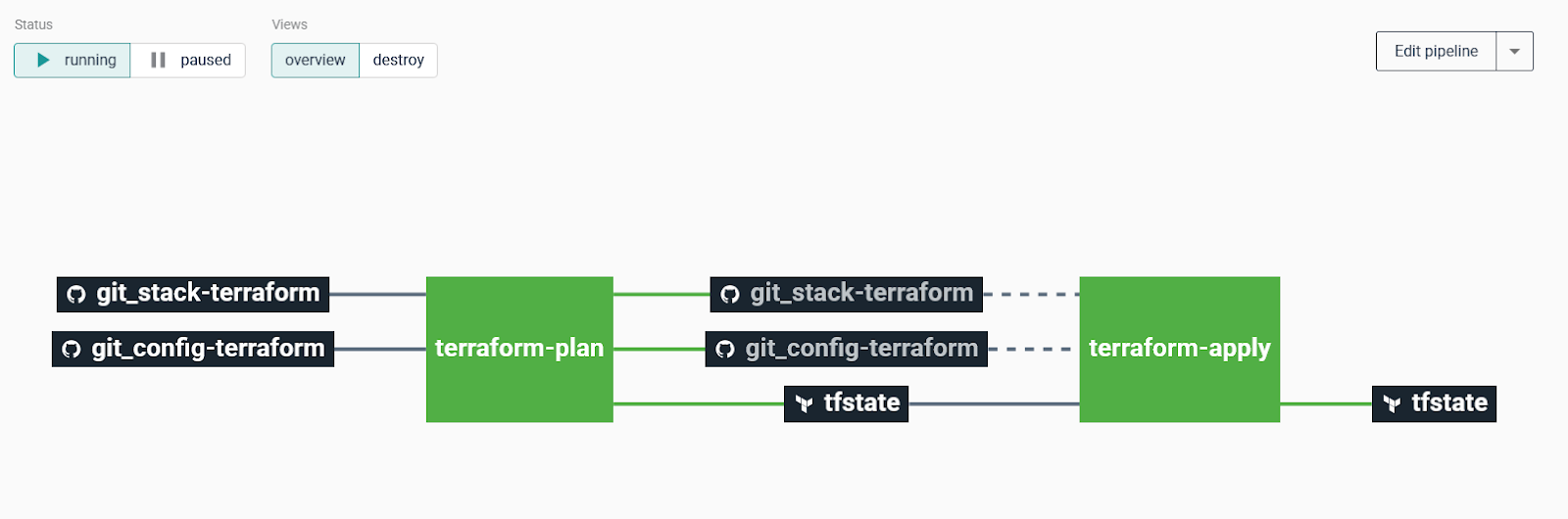
The pipeline ensures deployments follow a structured process without requiring manual intervention. It also manages Terraform state to keep track of existing resources and prevent conflicts. This automated workflow makes infrastructure provisioning more predictable while keeping costs in check as well.
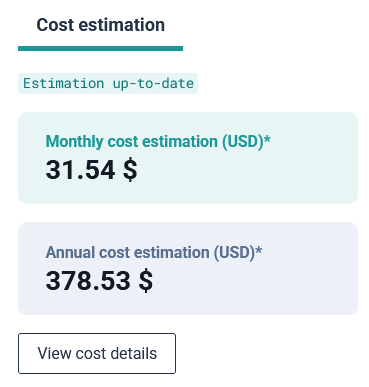
With real-time cost estimation, teams can compare instance types or adjust configurations before deployment to balance cost and performance. Once the resource configuration is finalized, it can be deployed directly from Cycloid, making sure that infrastructure changes are cost-optimized before affecting the cloud environment.
By integrating cost estimation with provisioning and ongoing cost tracking, Cycloid makes sure that cloud cost management is proactive rather than reactive. Instead of relying on post-deployment budgets and alerts, teams can optimize cloud spending at the time of provisioning, ensuring predictable and well-managed cloud costs.
Do you want to take control of your cloud costs before deploying to the infrastructure? Try Cycloid now and make every resource count.
Conclusion
Till now, you should have a clear understanding of how misconfigurations and unmanaged resources lead to high cloud costs. We covered how platform engineering, cost monitoring, and Cycloid help control expenses. By following these practices, teams can optimize cloud spending and avoid unexpected charges.
Frequently Asked Questions
-
How do you control cloud costs?
Cloud costs can be controlled by right-sizing resources, setting budgets and alerts, automating scaling, and regularly reviewing usage to eliminate waste. Using Infrastructure as Code (IaC) helps standardize provisioning and prevent over-allocation.
- How can you optimize costs with cloud computing?
Optimizing cloud costs involves using auto-scaling, spot instances, serverless computing, and reserved instances where applicable. Regular audits, enforcing tagging policies, and tracking expenses with cost-monitoring tools also help. -
How to save cost on cloud?
To save cloud costs, avoid idle resources, use cost-effective storage options, and leverage discounts like reserved and spot instances. Implement automation to scale resources only when needed.
-
How to control cost in Azure?
Azure costs can be controlled by setting up Azure Cost Management, enabling budgets and alerts, using reserved instances, and optimizing virtual machines and storage based on usage patterns.
-
What is Azure Cost Management tool?
Azure Cost Management is a built-in tool that helps track, analyze, and optimize cloud spending in Azure. It provides reports, cost alerts, and recommendations to manage expenses effectively.

Si vous ne vivez pas sous un rocher depuis un an et demi, il y a de fortes chances que vous ayez entendu parler de l'ingénierie des plates-formes. l'ingénierie des plates-formes. La dernière tendance du secteur promet de faire tout ce que DevOps a essayé de faire et a échoué, une fois de plus : alléger la charge de travail de vos développeurs, améliorer DevX, faire monter en flèche l'efficacité opérationnelle et transformer vos projets en rivières d'or.
En réalité, l'ingénierie de plateforme poursuit le processus entamé par DevOps. Avec l'ingénierie de plateforme, les dirigeants disposent d'un plan d'action pour construire des chaînes d'outils et des flux de travail qui permettent aux développeurs de tout niveau de compétence de disposer de capacités en libre-service. Il s'agit d'une solution complète qui améliore non seulement l'autonomie et la collaboration des développeurs, mais aussi la gestion des ressources et l'intégration de l'écosystème et des modules d'extension.
Vous comprenez pourquoi il s'agit d'une proposition extrêmement attrayante pour les services informatiques - et d'une entreprise très intimidante. Après tout, il faut près de 3 ans et 20 spécialistes dévoués pour commencer à obtenir des résultats tangibles. Et pourtant, Gartner prévoit que d'ici 2026, 80 % des services informatiques adopteront des équipes internes d'ingénierie des plateformes.
Il est évident que vous ne voulez pas être à la traîne, mais cela signifie-t-il que vous devez vous lancer dans la course dès maintenant ? Quand devriez-vous adopter l'ingénierie de plateforme ?
Examinons les facteurs qui font que votre organisation doit envisager sérieusement l'ingénierie de plateforme.{{cta('165511729744','justifycenter')}}
Quelle est l'urgence ?
2026 est plus proche que vous ne le pensez, et l'industrie se prépare à protéger ses opérations contre les problèmes d'efficacité, de durabilité et de talents. Trois raisons principales expliquent pourquoi les organisations tournées vers l'avenir s'orientent vers une plateforme d'ingénierie interne maintenant, et pas demain.
- Conserver les meilleurs talents
Les grands talents - DevOps, ingénieurs logiciels et de plateforme, architectes de solutions - veulent innover et résoudre les problèmes avec des technologies de pointe, au lieu de perdre du temps à dépanner les systèmes existants. L'ingénierie de plateforme rationalise les tâches complexes et résume les rouages des outils de développement en une belle interface utilisateur conviviale. Les entreprises qui adoptent des stratégies d'ingénierie de plateforme ont tendance à attirer et à conserver les meilleurs talents. Si vous tardez à le faire, vous risquez de les perdre au profit de la concurrence.
- Efficacité maximale
Une plateforme d'ingénierie s'occupe du travail ennuyeux que personne ne veut faire et minimise l'erreur humaine dans les tâches qui peuvent être automatisées. Cela vous permet de vous débarrasser d'une dette technique inutile et d'aller de l'avant de manière plus légère, moins lourde et plus rapide, en donnant à votre équipe brillante les moyens de faire son meilleur travail. Nous aimons considérer la fusion entre votre personnel et l'ingénierie de plateforme comme un moteur de distorsion, aidant votre organisation à aller audacieusement là où aucun homme n'est allé auparavant.
- Économiser les ressources
La planète ne peut pas attendre ! Les technologies de l'information jouent un rôle considérable dans notre impact global sur l'environnement - vous n'avez pas compris ? Les émissions de carbone liées à l'utilisation de l'informatique en nuage à l'échelle mondiale ont dépassé celles de l'aviation commerciale en 2023. Sans compter qu'il s'agit d'une ponction énorme sur les ressources propres de votre organisation. L'ingénierie de plateforme vous aide à garder un œil sur votre utilisation du cloud, en réduisant les ressources inutilisées et en évitant les dépassements de budget si nécessaire. Cela signifie une charge plus légère sur Terre et des économies de coûts en prime !
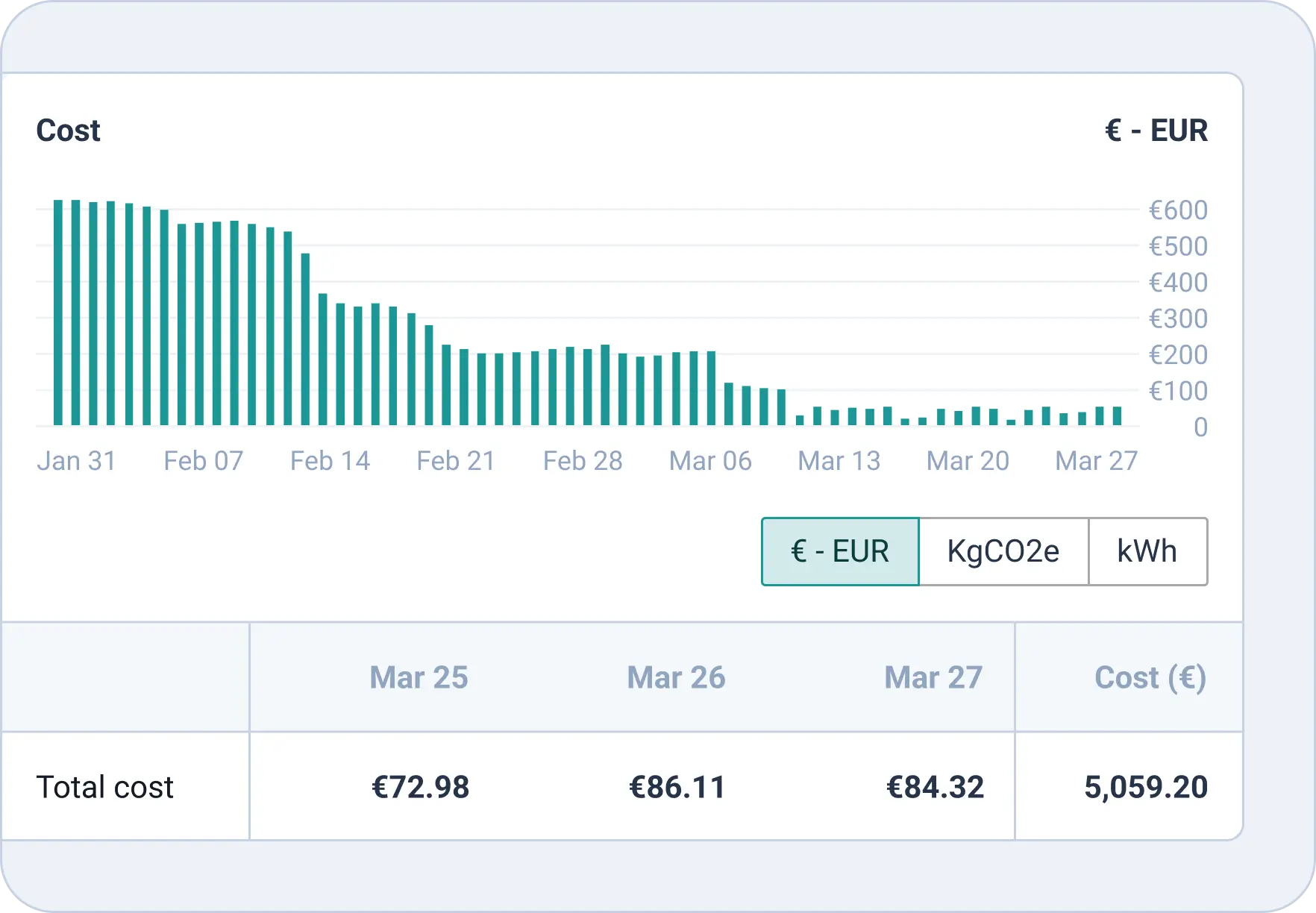
Quand devriez-vous adopter l'ingénierie de plateforme ?
Réponse courte : cela dépend. Réponse longue : cela dépend de l'ampleur de vos projets.
Lorsque votre organisation ou votre projet atteint un certain niveau de complexité, il est inévitable qu'une plateforme dédiée soit nécessaire pour prendre en charge vos applications, services ou produits. Voici quelques facteurs à prendre en compte pour déterminer s'il est temps d'investir dans l'ingénierie des plateformes :
- Défis d'échelle :
Vous éprouvez des difficultés à faire évoluer vos applications ou vos services pour répondre à une demande croissante ? C'est peut-être le signe que vous avez besoin d'une plateforme capable de fournir l'infrastructure et les outils nécessaires pour soutenir l'évolutivité. Une plateforme d'ingénierie peut vous aider à passer à la vitesse supérieure lorsque vous en avez besoin.
- Tâches répétitives :
Voici ce qu'aucun développeur ou DevOps ne veut faire : résoudre de manière répétée les 3 mêmes problèmes ou implémenter les 3 mêmes fonctionnalités à travers plusieurs projets. C'est un énorme gaspillage non seulement de la créativité de votre équipe, mais aussi des ressources de votre organisation. Une plateforme peut aider à standardiser ces processus et à améliorer l'efficacité, en éliminant les tâches répétitives et les erreurs humaines.
- Diverses charges de travail :
Arrêtez de dupliquer les infrastructures ! Lorsque votre organisation dispose d'applications ayant des exigences différentes, la quantité d'environnements peut rapidement devenir désordonnée et ingérable. L'ingénierie de plateforme fournit une infrastructure commune et un ensemble d'outils qui peuvent être partagés entre les équipes, réduisant ainsi la duplication des efforts.
- Besoins de collaboration :
À mesure que votre équipe s'agrandit, vos projets et vos produits se multiplient, ce qui signifie qu'il existe un réel danger de cloisonnement (et nous détestons les cloisonnements avec passion) et un réel besoin de collaboration. Une plateforme - pensez aux référentiels partagés, au contrôle de version et aux revues de code - garantira le bon fonctionnement de toutes vos applications et permettra à vos équipes de tisser des liens autour d'un travail bien fait ensemble.
- La maintenabilité et la stabilité :
Imaginez la situation : votre équipe DevOps est constamment en train d'éteindre des incendies et de lutter pour maintenir le système, tandis que vos clients déplorent les pannes incessantes de vos applications. Un cauchemar, n'est-ce pas ? Si c'est votre réalité, c 'est le moment d'adopter une plateforme. L'ingénierie de plateforme peut contribuer à rationaliser les opérations, à automatiser les tâches et à améliorer la fiabilité générale.
- Optimisation des coûts :
Au fur et à mesure que vos projets prennent de l'ampleur, l'utilisation des ressources sur les différentes plates-formes en nuage augmente également. Sans surveillance, elle peut facilement devenir incontrôlable. La création d'une plateforme peut contribuer à optimiser les coûts en normalisant l'infrastructure, en améliorant l'utilisation des ressources et en permettant une meilleure allocation des ressources en fonction des schémas d'utilisation (tout en contribuant à sauver la planète !).
- Sécurité et conformité :
Respecter les normes de sécurité et de conformité est une tâche délicate, mais le pire, c'est qu'elle est sujette à des erreurs de la part des utilisateurs. Si vos applications doivent respecter des exigences spécifiques en matière de sécurité ou de conformité, une plateforme peut fournir les fonctions de sécurité et les contrôles nécessaires pour garantir que tous les verrous adéquats sont en place au sein de votre organisation.
- Croissance future :
En fin de compte, l'ingénierie des plates-formes consiste à préparer l'avenir de votre entreprise. Se débarrasser de l'infrastructure existante, industrialiser les déploiements manuelsou toute croissance en termes d'utilisateurs, de données ou de fonctionnalités - une plateforme peut vous aider à évoluer.
- Stratégie ESG :
Si votre organisation est très attachée aux objectifs ESG mais a besoin de solutions technologiques capables d'évoluer avec elle, une plateforme vous aidera à réduire votre empreinte environnementale, à sécuriser vos données et à utiliser l'IA de manière responsable. Rappelez-vous, d'ici 2026, toutes les organisations opérant en Europe devront rendre compte de leur impact environnemental. Pourquoi attendre cette date si vous pouvez vous attaquer à l'ESG dès maintenant ?

Quelles sont les industries qui doivent mettre en œuvre l'ingénierie de plateforme en premier ?
Votre secteur d'activité peut être le facteur décisif dans l'adoption ou non d'une plateforme d'ingénierie interne. Les vétérans chevronnés, dotés d'infrastructures patrimoniales, comme les banques, les assurances, les soins de santé, la logistique et l'industrie manufacturière, pourraient être les premiers sur le carreau. Ces "anciens" sont en plein mode de survie, réorganisant leurs systèmes grâce à des stratégies de migration par étapes et à des solutions de cloud hybride. Pour ces secteurs, l'ingénierie des plateformes est avant tout une question de modernisation, un coup d'accélérateur qui leur permettra de rester en phase avec les exigences numériques croissantes. En tant que telle, une plateforme peut aider à mettre en œuvre des architectures microservices pour plus d'agilité et donner la priorité aux mesures de sécurité et de conformité.
À l'opposé, vous avez les jeunes pousses : le développement de logiciels et la FinTech. Ces personnes partent de zéro et construisent quelque chose de vraiment révolutionnaire. L'ingénierie de plateforme aide à construire des solutions cloud-natives avec des pratiques DevOps pour une itération rapide. La conteneurisation et les technologies sans serveur garantiront l'évolutivité. Et, en intégrant l'IA/ML pour des perspectives améliorées et l'automatisation, vous pouvez maintenir un fort accent sur l'agilité et l'innovation.
Ne paniquez pas - faites confiance à votre instinct
Se lancer dans l'ingénierie de plateforme, c'est un peu comme construire Rome : cela demande du temps et de la patience. Si vous avez vu votre cas d'utilisation dans ce blog, il n'y a pas lieu de s'inquiéter. Grâce à la tendance actuelle et aux investissements dans le développement des meilleures pratiques et solutions, vous êtes sûr d'accélérer votre processus de livraison.
N'oubliez pas qu'il existe différents niveaux d'ingénierie de plateforme pour répondre à vos besoins spécifiques. Que vous commenciez par un simple portail en libre-service ou que vous alliez plus loin dans l'écosystème, il existe une solution adaptée à vos besoins. Pour en savoir plus, n'hésitez pas à consulter notre eBook sur le sujet.
Et si vous pensez que le moment est venu, visitez le site suivant Pourquoi maintenant et pas demain ? | Adoptez l'ingénierie des plates-formes
...
If you’ve not been living under a rock for the last year and a half, chances are you’ve heard of Platform Engineering. The latest industry trend promises to do everything DevOps tried to do and failed, yet again: lighten your devs’ workload, improve DevX, skyrocket operational efficiency, and turn your projects into rivers of gold.
In truth, Platform Engineering continues the process DevOps started. With PE, leaders have an actionable plan to build toolchains and workflows that empower developers of any skill level with self-service capabilities. It’s an all-round solution that not only improves devs’ autonomy and collaboration, but also enhances resource management, and provides ecosystem and plug-in integration.
You see why it’s an extremely attractive proposition for IT departments - and a very daunting undertaking. After all, it takes nearly 3 years and 20 dedicated specialists to start seeing tangible results. And yet, Gartner predicts that by 2026, 80% of IT departments will adopt internal platform engineering teams.
Obviously, you don’t want to be left behind, but does this mean you should join the race now? When should you adopt Platform Engineering?
Let's look at the factors that mean your organization needs to consider platform engineering seriously.{{cta('165511729744','justifycenter')}}
What's the urgency?
2026 is looming closer than you may think, and the industry is gearing up to future-proof its operations against efficiency, sustainability, and talent setbacks. There are 3 main reasons why future-thinking organisations are moving towards an internal engineering platform now, and not tomorrow.
- Keep top talent
Great talent - DevOps, software and platform engineers, Solution Architects - want to innovate and solve challenges with cutting-edge technology, instead of wasting time troubleshooting legacy systems. Platform engineering streamlines complex tasks and abstracts the nuts and bolts underneath dev tools into a lovely user-friendly UI. Companies that adopt platform engineering strategies tend to attract and keep the top talent. Delaying will risk you losing them to the competition.
- Maximum efficiency
An engineering platform takes care of the boring work nobody wants to do and minimizes human error in tasks that can be automated. This helps you shed unnecessary technical debt and move forward lighter, leaner, and faster, empowering your brilliant team to do their best work. We like to think of the fusion between your people and platform engineering as a warp engine, aiding your organisation to boldly go where no man has gone before.
- Save resources
The planet cannot wait! IT plays a huge role in our overall environmental impact - haven’t you got the memo? Carbon emissions from global cloud usage have exceeded those of commercial aviation in 2023. Not to mention it’s a huge drain on your organisation’s own resources. Platform engineering helps you keep an eye on your cloud usage, slashing unused resources and preventing budget overruns where needed. This means a lighter load on Earth and cost savings as a nice bonus!
When should you adopt Platform Engineering?
Short answer - it depends. Long answer - it depends on the level of the scale of your projects.
When your organization or project reaches a certain level of complexity, it will inevitably warrant a dedicated platform to support your applications, services, or products. Here are some factors to consider when determining if it's time to invest in platform engineering:
- Scaling challenges:
Are you experiencing difficulties in scaling your applications or services to meet growing demand? That might be a sign that you need a platform that can provide the necessary infrastructure and tools to support scalability. An engineering platform can help you rev up when you need it.
- Repetitive tasks:
Here’s what no dev or DevOps wants to do: repeatedly solve the same 3 problems or implement the same 3 features across multiple projects. It’s a huge waste not only of your team’s creativity but your organization’s resources. A platform can help standardize these processes and improve efficiency, eliminating repetitive tasks and human error.
- Diverse workloads:
Stop duplicating infrastructures! When your organization has applications with different requirements, the amount of environments can quickly become messy and unmanageable. Platform engineering provides a common infrastructure and set of tools that can be shared across teams, reducing duplication of effort.
- Collaboration needs:
As your team grows, your projects and products multiply, which means there’s a real danger of siloes (and we hate siloes with a passion) and a real need for collaboration. A platform - think shared repositories, version control, and code reviews - will make sure all your applications are running smoothly and your teams bond over work well done together.
- Maintainability and stability:
Picture this: your DevOps team are constantly putting out fires and struggling to maintain the system, while your clients bemoan your apps’ continuous crashing. Nightmare, isn’t it? Now, if that is your reality, this is your sign to adopt a platform. Platform Engineering can help streamline operations, automate tasks, and improve overall reliability.
- Cost optimization:
As your projects grow, resource usage across various cloud platforms grows with it. Without oversight, it can easily get out of hand. Building a platform can help optimize costs by standardizing infrastructure, improving resource utilization, and enabling better resource allocation based on usage patterns (and help save the planet too!)
- Security and compliance:
Meeting security and compliance standards is tricky business, but the worst part is that it’s prone to user error. If your applications need to adhere to specific security or compliance requirements, a platform can provide the necessary security features and controls to ensure all the right locks are in place across your organization.
- Future growth:
At the end of the day, platform engineering is all about future-proofing your business. Getting rid of legacy infra, industrializing manual deployments, or any growth in terms of users, data, or features - a platform can help you scale.
- ESG strategy:
If your organization is big on ESG goals but needs tech solutions that can grow with it, a platform will help shrink your environmental footprint, keep data safe, and use AI responsibly. Remember, by 2026 all organisations operating in Europe will need to report on their environmental impact. Why wait until then if you can tackle ESG now?
Which industries must implement Platform Engineering first?
Your industry may be the deciding factor in whether to adopt an internal engineering platform or not. The seasoned veterans, sporting legacy infrastructures, such as Banking, Insurance, Healthcare, Logistics, and Manufacturing, may be the first on the cutting block. These “oldies” are in full-on survival mode, revamping their systems through phased migration strategies and leveraging hybrid cloud solutions. Platform engineering for these industries is all about modernization, a jumpstart to keep them walking in line with the growing digital demands. As such, a platform can help to implement microservices architectures for agility and prioritise security and compliance measures.
In contrast, you've got the up-and-comers: software development and FinTech. These folks are all about starting from scratch and building something truly groundbreaking. Platform engineering helps to build cloud-native solutions with DevOps practices for rapid iteration. Containerization and serverless technologies will ensure scalability. And, by integrating AI/ML for enhanced insights and automation, you can maintain a strong focus on agility and innovation.
Don’t panic - trust your instinct
Embarking on platform engineering is akin to building Rome - it takes time and patience. If you’ve seen your use case in this blog, there's no need to fret. With the ongoing trend and investments in developing best practices and solutions, you're sure to accelerate your delivery process.
Remember, there are varying levels of platform engineering to suit your specific needs. Whether you're starting with a simple self-service portal or delving into the broader ecosystem, there's a solution tailored for you. For more insights, be sure to explore our eBook on this topic.
And if you think the time is now, visit Why now, not tomorrow? | Adopt Platform Engineering
...
On July 31st, 2023 the European Commission announced new sustainability reporting in the European Union. The European Sustainability Reporting Standards (ESRS) will change how European businesses (and companies that do business in the EU) are required to report on their sustainability and ESG.
The standards cover the full range of environmental, social, and governance issues, including climate change, biodiversity, and human rights. They also provide information for investors to understand the sustainability impact of the companies in which they invest. Here’s what the timeline looks like.
It's important to note that while these standards have been announced, they are not yet legally binding. However, they serve as a powerful indicator of the direction Europe is taking regarding business sustainability. It's clear that the winds of change are blowing strongly in favor of greater transparency and responsibility in the corporate world. And we’re all for it!
Tech Sustainability and GreenOps
Sustainable IT practices are a huge part of Cycloid’s mission. We’ve spoken before about the concept of GreenOps (and you might have seen that term around), which refers to a framework for organizations to start understanding and quantifying the environmental impacts of their IT strategies whilst promoting a culture of environmental sobriety that flows through a workforce. At its heart, this methodology encourages a more mindful consumption of IT resources which are invariably dependent on planetary resources. We hope that a GreenOps strategy might be the first step for many companies to start taking responsibility for their environmental impact.
Keen to learn more? Download our Definitive Guide to GreenOps - the only ebook you’ll ever need to get your green strategies on track!
{{cta('152dd5a8-4b85-4758-967b-ab2aafb307f2')}}
One of the main areas of GreenOps where you can make a real impact is the cloud. As businesses increasingly rely on cloud services for data storage, computing power, and software delivery, the environmental footprint of these data centers becomes an essential part of the sustainability equation.
The current “open bar” approach to cloud infrastructure generates enormous amounts of carbon emissions, wasting valuable planetary resources, as we cover in a few blog posts. The good news is that there is a way to fix it - while also providing you with the necessary ESRS data.
Cloud Carbon Footprint Reports
Cycloid’s Cloud Carbon Footprint tool is part of our FinOps module and it displays your carbon emissions alongside your cloud spending. This means that you get accurate reports on the environmental impact of your cloud usage with the same granularity as your financial reports, so you can easily identify the culprit project, team or the cloud provider and eliminate unnecessary expenses.
By streamlining your operations, you're not only lowering energy consumption and reducing your carbon footprint but also trimming your expenses. It's a win-win-win situation – you, your budget, and the environment all benefit.
It currently supports the 3 main public clouds (AWS, Azure and GCP), but we’re working on adding more.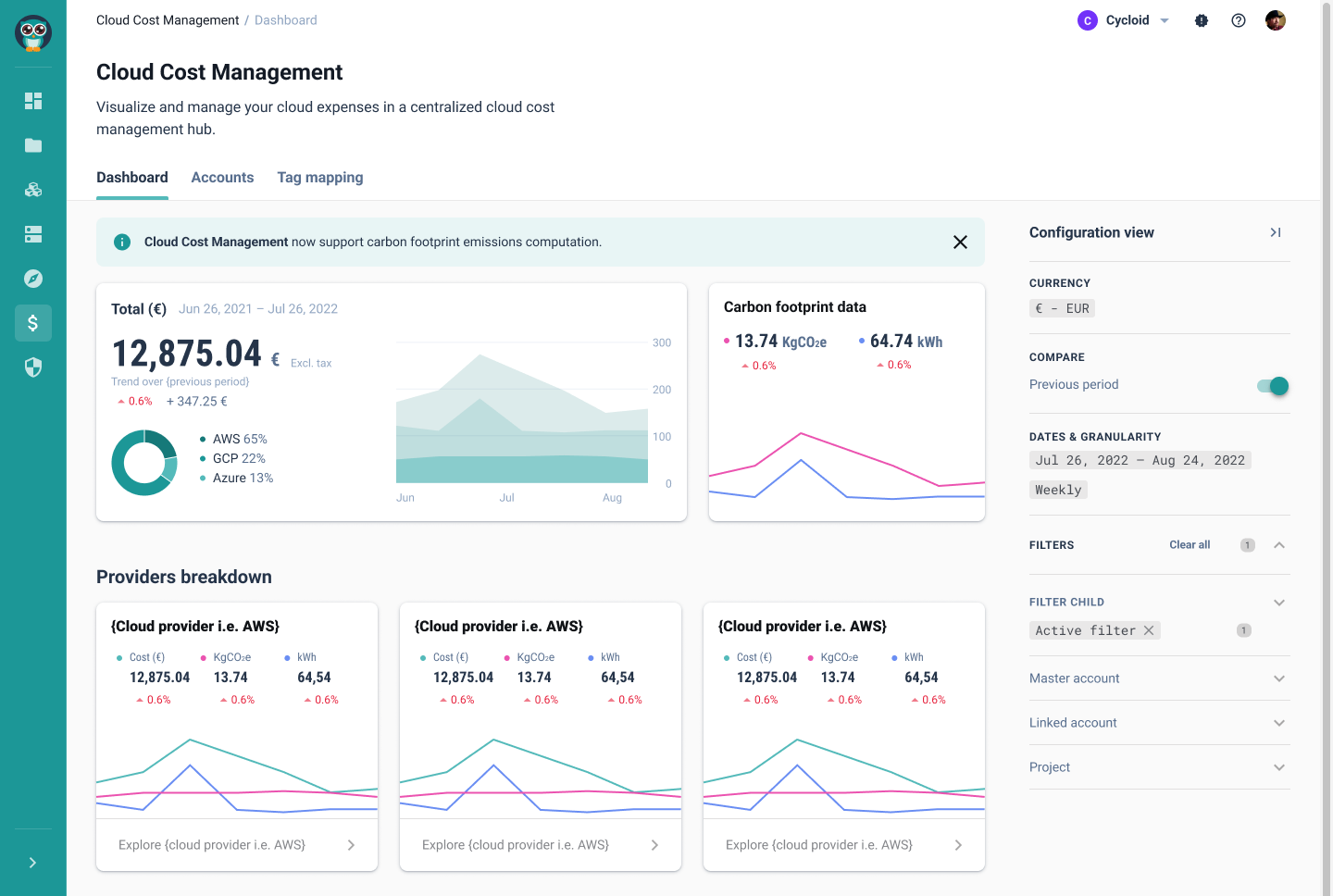
You can download custom reports in any format to enhance your ESRS data with more accurate and granular data.
Using Cloud Carbon Footprint is not just about ticking a box to meet regulatory requirements; it's about embracing the spirit of sustainability and making a positive impact on the planet.
Conclusion
While the European Sustainability Reporting Standards indicate a promising shift towards greater corporate responsibility, tools like the Cloud Carbon Footprint ensure that your digital infrastructure is not only compliant but actively contributing to a more sustainable and eco-friendly future.

Le 31 juillet 2023, la Commission européenne a annoncé une nouvelle forme de communication de données sur la durabilité au sein de l’Union européenne. Les normes ESRS (normes européennes de reporting sur la durabilité) vont bouleverser les habitudes en matière de communication de données des entreprises européennes (et de celles qui génèrent un chiffre d’affaires dans l’UE). En effet, elles devront répondre à des nouvelles prérogatives quant à leurs rapports sur la durabilité et la Responsabilité Sociétale des Entreprises (RSE).
Ces normes s’appliquent aux échelles environnementale, sociale, et de gouvernance, ce qui comprend le dérèglement climatique, la biodiversité et les droits humains. Elles permettent également d’informer les investisseurs au sujet des répercussions environnementales des entreprises auxquelles ils sont associés. Voici à quoi ressemble la chronologie de leur application.

Il faut retenir que malgré l’annonce de ces normes, elles ne sont pas encore entrées en vigueur du point de vue du droit. Cependant, elles représentent une prise de position claire de la part de l’UE quant à la durabilité des entreprises. Un vent nouveau souffle sur le monde des affaires, et il est manifestement en faveur de plus de transparence et de responsabilité ; pour nous, il s’agit d’excellentes nouvelles !
Durabilité technologique et GreenOps
Les pratiques informatiques durables font partie intégrante de la raison d’être de Cycloid. Nous avons déjà parlé du concept du GreenOps (et vous avez certainement eu l’occasion de l’apercevoir), qui se réfère à un cadre employé par les organisations pour comprendre et mesurer les répercussions environnementales de leurs stratégies informatiques tout en encourageant la sobriété écologique parmi toute l’équipe. L’essence de cette méthodologie repose sur une consommation plus consciencieuse des outils informatiques, qui dépendent systématiquement des ressources de la planète. Nous espérons qu’une stratégie GreenOps sera la première étape de la sobriété digitale de nombreuses entreprises.
Pour en savoir plus, téléchargez notre Definitive Guide to GreenOps, le seul ebook qu’il vous faut pour lancer votre stratégie de mise au vert !
{{cta('168667680044','justifycenter')}}
Le coût associé au gaspillage du Cloud représentait 168 Milliards de dollars en 2023 (source Gartner + Flexera). Le cloud est donc un des endroits où vous pouvez faire bouger les choses grâce au GreenOps. Comme les entreprises comptent de plus en plus sur les services du cloud pour le stockage de données, la puissance de calcul, et la livraison de logiciels, l’empreinte environnementale de ces centres de données devient une composante fondamentale de la question écologique.
L’approche « open bar » actuelle pour l’infrastructure cloud produit des quantités énormes d’émissions carbone, ce qui conduit à un gaspillage des ressources planétaires (nous en parlons dans plusieurs publications dans notre blog). Heureusement, il est possible d’y remédier, tout en récupérant les données nécessaires pour les normes ESRS.
Les rapports sur l’empreinte carbone du cloud
L’outil Cloud Carbon Footprint de Cycloid fait partie de notre module FinOps et il affiche vos émissions de carbone en plus de vos dépenses sur le cloud. Cela signifie que vous avez accès à des rapports précis sur les répercussions environnementales de votre utilisation du cloud avec autant de granularité que pour vos rapports financiers. Ainsi vous pourrez identifier aisément le projet, l’équipe, ou fournisseur cloud « coupable » et éliminer les dépenses inutiles.
En optimisant vos opérations, non seulement vous réduisez votre consommation énergétique et votre empreinte carbone, mais vous diminuez aussi vos dépenses. Tout le monde y gagne : vous, votre budget, et la planète.
Pour l’instant, l’outil est compatible avec les trois serveurs cloud publics principaux (AWS, Azure, et GCP), mais nous travaillons à élargir cet éventail.
Les rapports sont personnalisables et téléchargeables dans plusieurs formats afin d’enrichir vos données ESRS d’informations plus précises.
Utiliser Cloud Carbon Footprint dépasse la simple satisfaction de critères institutionnels : il s’agit de s’approprier l’esprit de la durabilité pour contribuer à la protection de la planète.
Conclusion
Dans le contexte d’une grande responsabilisation du monde des affaires annoncée par les normes européennes d’information sur la durabilité, des outils comme Cloud Carbon Footprint garantissent non seulement une infrastructure numérique en règle mais aussi votre contribution à un avenir plus durable et vert.




